


Ein Cloud-Ausfall kann Unternehmen auf verschiedenen Ebenen treffen, an die man zunächst gar nicht denkt. Gut, wenn man vorbereitet ist.
Kunden gelangen nicht mehr in ihr Konto, die App hängt, Mitarbeiter werden aus ihren Anwendungen abgemeldet. Solche Fehlerbilder sind das erste Anzeichen dafür, dass tief in der globalen Cloud-Infrastruktur eine Störung begonnen hat, die eine Kette von Folgefehlern auslöst.
Coud-Computing ist nicht immer günstiger als eigene IT-Infrastruktur
Die These dabei: Gefährlich werden dabei vor allem die versteckten Abhängigkeitsketten, die kaum jemand vollständig kennt, und die Frage, ob das eigene Team im Ernstfall überhaupt noch handlungsfähig bleibt. Wenn Basisdienste wie DNS, ein globales Content Delivery Network, die Steuerungsebene des Anbieters oder der zentrale Identitätsdienst wegbrechen, fallen nicht allein die direkt betroffenen Workloads aus. Es trifft auch Systeme, die scheinbar sicher in einer anderen Region oder sogar im eigenen Rechenzentrum laufen, sofern sie sich für Anmeldung oder Routing auf genau diese zentralen Dienste verlassen.
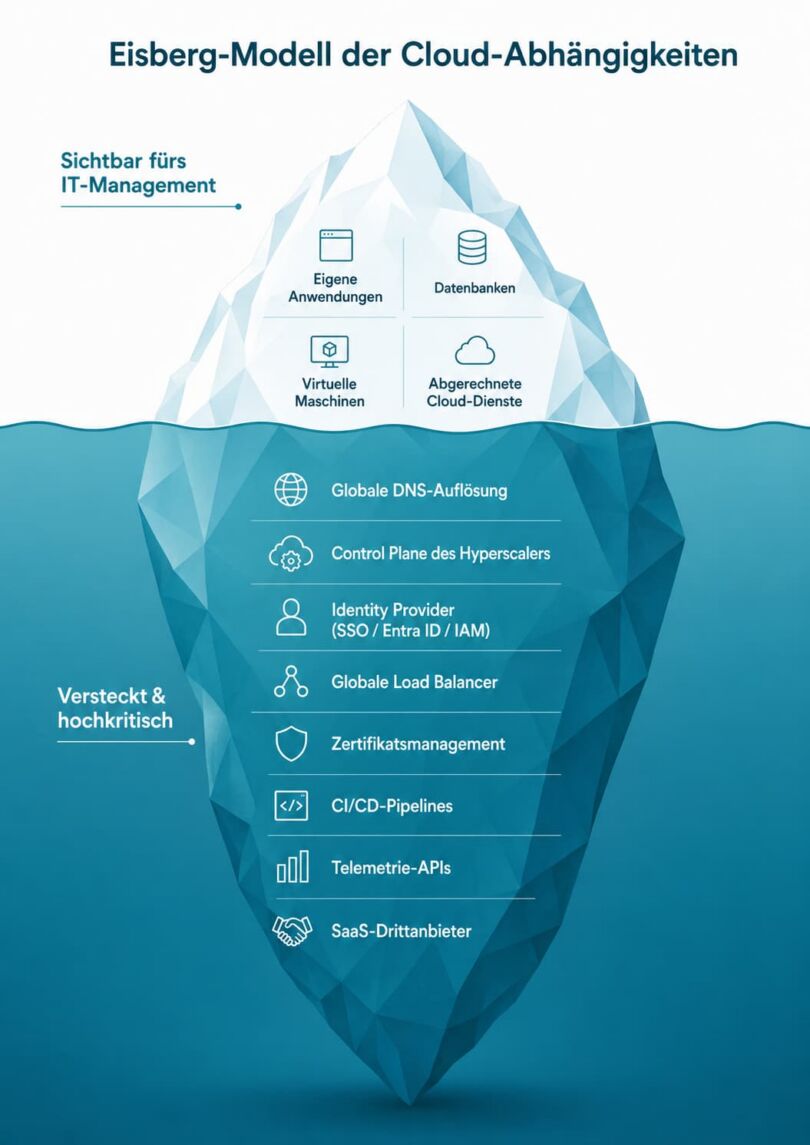
Abbildung: Eisberg-Modell der Cloud-Abhängigkeiten
Eine Generalkritik an der Cloud ist damit nicht beabsichtigt. Die Skalierbarkeit und Innovationskraft von Amazon Web Services (AWS), Microsoft Azure oder Google Cloud bleiben für die meisten Unternehmen konkurrenzlos.
Wir möchten IT-Verantwortlichen, Architekten und Entscheidern die Möglichkeit zu einem praxistauglichen Resilienz-Check geben. Anlass sind die beiden großen Störungen im Oktober 2025, die innerhalb weniger Tage zwei der größten Cloudanbieter trafen. Sie haben offengelegt, wie wenig ein zugesichertes Service Level Agreement (SLA) wert ist, wenn der Wiederanlauf nie geübt wurde, und dass eine grobe Verteilung über mehrere Zonen noch lange keine Disaster-Recovery-Strategie ergibt.
Was beim letzten großen Hyperscaler-Ausfall passiert ist
Wer aus diesen Vorfällen lernen will, muss verstehen, wie sie technisch abliefen. Zwei Ereignisse taugen als Lehrstück: der Ausfall von AWS am 20. Oktober 2025 sowie die globale Störung von Azure Front Door am 29. Oktober 2025. Den Schaden verursachte jeweils ein Softwarefehler in einer globalen Routing- oder Steuerungskomponente.
Der AWS-Vorfall zog sich bis zum späten Nachmittag des 20. Oktober. Seinen Ursprung hatte er ausgerechnet in der Region US-EAST-1 in Nord-Virginia: der ältesten und größten Region des Anbieters, auf deren Metadaten viele globale Dienste zugreifen. Im Kern lag das Problem laut der technischen Analyse von ThousandEyes in der DNS-Auflösung für die API-Endpunkte des Datenbankdienstes DynamoDB.
Betroffen waren Gaming-Plattformen, Finanzdienstleister und Unternehmenssysteme rund um den Globus, auch solche mit Workloads in Europa oder Asien, solange sie für Authentifizierung (IAM, STS) oder Service Discovery an Endpunkten in US-EAST-1 hingen. Bei Vorfällen dieser Tragweite veröffentlicht AWS sogenannte Post-Event Summaries, die den Ablauf im Detail dokumentieren.
Nur zehn Tage später traf es Microsoft Azure. Am 29. Oktober 2025 fiel Azure Front Door (AFD) zusammen mit dem Azure CDN aus: die Schicht, über die ein Großteil des eingehenden Webverkehrs läuft.
Die Ursache lag im globalen Rollout-Prozess. Zunächst ging eine fehlerhafte, über zwei Control-Plane-Versionen hinweg inkompatible Konfigurationsänderung in die Verteilung. Eigentlich sollen Canary-Deployments genau das früh stoppen, doch sie taten es nicht, weil der Fehler in der Datenebene rein asynchron auftrat und die Health Check während des Rollouts ohne Beanstandung durchliefen.
Microsoft hat die Lehren aus diesem Vorfall inzwischen ausführlich beschrieben. Die fehlerhafte Konfiguration breitete sich global aus und überschrieb den letzten funktionierenden Stand. In der Folge stürzten zahlreiche Edge-Knoten ab. Externe Beobachter sahen sofort Verbindungsabbrüche, HTTP-Fehler 403 und 502 sowie DNS-Probleme direkt am Netzwerkrand — lange bevor eine Anfrage überhaupt einen Backend-Server erreichte.
Die Folgen waren weithin spürbar. Ausfälle bei Microsoft 365, Teams, Outlook und Entra ID sowie bei Endkundendiensten wie Xbox Live. Der Schaden reichte bis in andere Branchen: Buchungssysteme von Fluggesellschaften wie Alaska Airlines und Hawaiian Airlines fielen aus, ebenso Systeme im Flughafenbetrieb. Bemerkenswert dabei: Selbst das Azure-Portal, über das Administratoren sonst Gegenmaßnahmen einleiten, war zeitweise nicht erreichbar. Microsoft musste es in einer manuellen Notaktion von Azure Front Door abkoppeln, um überhaupt wieder Zugriff zu bekommen.
Die Muster ähneln sich verblüffend. Beide Male war ein globaler Edge-Dienst oder die Steuerungsebene einer Kernregion das Problem. DNS, Control Plane, Identitätsverwaltung und am Ende das Verwaltungsportal selbst bildeten den Flaschenhals. Von dort breitete sich der Schaden über SaaS-Dienste, Entwicklungs-Pipelines und Kundenportale aus.
Cloud-Ausfälle sind Abhängigkeits-Ausfälle
Beide Vorfälle zeigen, dass ein Umdenken bei der Risikobewertung von Cloud-Diensten notwendig ist. Eine moderne Cloud besteht aus tausenden lose gekoppelten Microservices, die fortlaufend miteinander kommunizieren. Fällt etwas aus, handelt es sich deshalb fast immer um einen Abhängigkeits-Ausfall. Für die Praxis lohnt der Blick auf den Unterschied zwischen direkten und indirekten Abhängigkeiten.
Eine direkte Abhängigkeit ist leicht zu greifen: Eine Anwendung läuft zum Beispiel auf einer bestimmten Azure-SQL-Instanz oder einem EC2-Cluster. Fällt dieser Dienst aus, steht die Anwendung. Dieses Risiko kennt jeder, es lässt sich messen und mit klassischer Redundanz wie Datenbankspiegelung abfedern.
Schwieriger sind die indirekten Abhängigkeiten, die oft tief im Code stecken und kaum dokumentiert sind. Sie entstehen, weil Hyperscaler bequeme globale Querschnittsdienste anbieten, die sich mit wenig Aufwand einbinden lassen. Das beste Beispiel sind globale Identitätsdienste und Single Sign-on. Zero-Trust-Architekturen bündeln die Anmeldung über Dienste wie Microsoft Entra ID oder AWS IAM. Wenn die Edge-Schicht wie beim Azure-Ausfall keine Anmeldeanfragen mehr an den Identitätsdienst durchreicht, hilft es niemandem, dass die eigentliche Fachanwendung in einer unberührten europäischen Region tadellos läuft. Weder Mitarbeiter noch Kunden können sich anmelden. Der Dienst ist praktisch nicht erreichbar, obwohl die Server zu hundert Prozent verfügbar sind. Ähnlich beim DNS, dem Telefonbuch des Internets: Fallen Auflösung oder Resolver aus, wie bei AWS in US-EAST-1, finden sich die Microservices schlicht nicht mehr, unabhängig davon, wie teuer und redundant die darunterliegende Hardware ist.
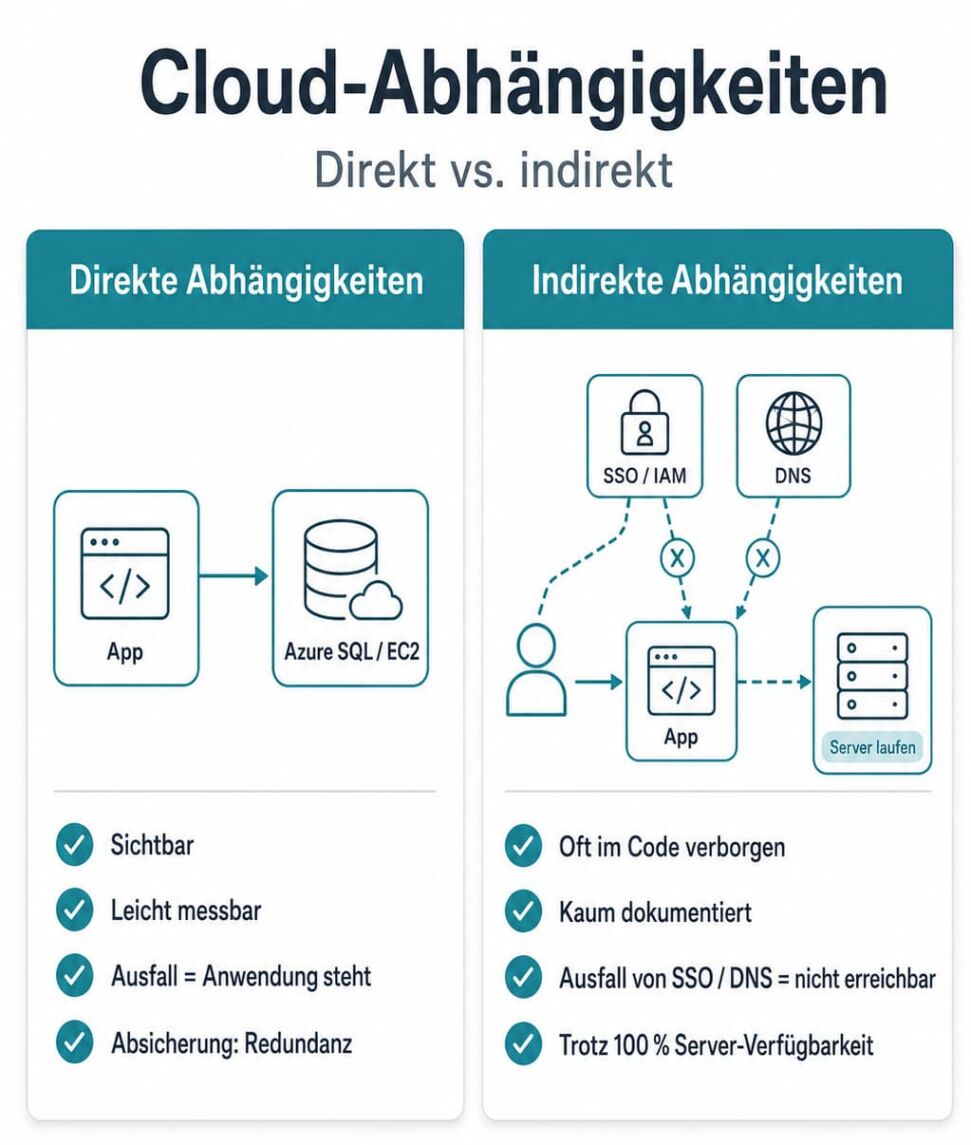
Abbildung: Ausfall in der Cloud: direkte und indirekte Abhängigkeiten
Es gibt weitere Ketten, die in Risikobetrachtungen oft fehlen. CI/CD-Pipelines hängen an Code-Repositories, Artefakt-Speichern und Automatisierungsservern, die meist ebenfalls in der Cloud liegen. Steht die Control Plane, können DevOps-Teams keinen Fix mehr ausrollen und keine fehlerhafte Konfiguration zurücknehmen, und das ausgerechnet in dem Moment, in dem es am dringendsten gebraucht wird. Werkzeuge für Monitoring, Alarmierung und Chat wie Teams, Slack, PagerDuty sind im Krisenfall die Lebensader. Brechen sie weg, verliert der Krisenstab seine Kommunikations- und Koordinationsbasis.
Die folgende Übersicht zeigt, wie breit diese versteckten Abhängigkeiten streuen und was passiert, wenn der jeweilige Dienst ausfällt.
| Kategorie der Abhängigkeit | Typische Cloud-Services | Auswirkung beim Ausfall des Dienstes |
| Identität & Zugriff (IAM/SSO) | Microsoft Entra ID, AWS IAM, AWS Cognito, Auth0 | Nutzer bleiben komplett ausgesperrt. Keine Logins für Endkunden, gesperrte Admin-Zugänge, Microservices können sich nicht mehr gegenseitig autorisieren. |
| Netzwerk & Routing am Edge | Azure Front Door, AWS Route 53, Cloudflare, Azure CDN | Globale Nicht-Erreichbarkeit. Webseiten laden nicht, APIs laufen in Timeouts (wie beim Azure-Vorfall). Eingehender Verkehr erreicht die gesunden Backend-Server nicht. |
| Betrieb & Observability | Azure Monitor, AWS CloudWatch, Datadog | Blindflug für Administratoren. Auto-Scaling versagt mangels Metriken, bei Folgefehlern bleibt die Alarmierung aus. |
| Entwicklung & CI/CD | GitHub Actions, Azure DevOps, AWS CodePipeline | Code-Freeze wider Willen. Hotfixes, Rollbacks und Notfall-Konfigurationen lassen sich nicht mehr in die Produktion bringen. |
| Kommunikation & Ticketing | Microsoft Teams, Exchange Online, Jira, ServiceNow | Das Incident-Management bricht zusammen. Der Krisenstab kann sich nicht koordinieren, Kundentickets bleiben liegen. |
| Business-SaaS & Drittanbieter | Salesforce, SAP (Cloud), Stripe, Zendesk | Vertrieb, Support und Zahlungsabwicklung stehen still, weil diese Anbieter im Hintergrund oft selbst auf AWS oder Azure laufen. |
Tabelle: Versteckte Abhängigkeiten in der Cloud
Hinzu kommen Kaskaden über externe SaaS-Lösungen. Ein Unternehmen kann seine eigene Software noch so sorgfältig über mehrere Anbieter verteilt haben; wenn CRM, ERP, Payment-Gateway oder Ticketsystem im Hintergrund auf demselben Hyperscaler laufen, stehen die Geschäftsprozesse dennoch still. Für Entscheider heißt das: Wer beim Risiko nur auf die eigenen Compute- und Storage-Workloads schaut und Identität, DNS und Routing ausblendet, unterschätzt das tatsächliche Risiko erheblich.

Abbildung: DNS-Fehler und Kettenreaktion in der Cloud
Warum klassische Hochverfügbarkeit oft nicht reicht
Jahrzehntelang stützte sich Notfallvorsorge auf Hochverfügbarkeit. In der Cloud heißt das meist: Workloads über mehrere Verfügbarkeitszonen verteilen (Multi-AZ) oder, bei wichtigeren Systemen, über mehrere Regionen spiegeln (Multi-Region). Die Ausfälle 2025 haben gezeigt, dass diese Konzepte blinde Flecken haben und eine Sicherheit suggerieren, die real nicht besteht.
Zunächst die Begriffe: Multi-AZ (AZ für “Availability Zone”) schützt zuverlässig gegen lokale, physische Probleme: Stromausfall, Brand, Wasserschaden oder eine gekappte Leitung in einem Rechenzentrum. Gegen einen Softwarefehler oder eine fehlerhafte Konfiguration, die der Anbieter über die gemeinsame Steuerungsebene einer ganzen Region ausrollt, hilft das nicht. Multi-Region ist robuster, weil es physisch und logisch trennt. Doch auch das schützt nicht automatisch, wenn ein globaler Dienst wie Azure Front Door, das globale Entra ID oder globale IAM-Rollen von einem systemweiten Fehler erwischt werden, wie es im Oktober 2025 geschah.
Ein weiterer Punkt sind die Backups. Datensicherungen sind unverzichtbar und teils gesetzlich vorgeschrieben, um Daten vor Ransomware oder Bedienfehlern zu schützen. Eine Wiederanlaufstrategie ersetzen sie allerdings nicht. Ein einwandfreies Backup in einem S3-Bucket oder Azure Blob Storage nützt wenig, wenn das Portal zum Auslösen der Wiederherstellung nicht erreichbar ist, oder wenn der Identitätsdienst ausfällt und sich niemand an der Notfallumgebung anmelden kann, um die Restore-Skripte zu starten.
Auch die Fixierung auf SLAs ist trügerisch. Eine zugesicherte Verfügbarkeit von 99,99 Prozent, also unter einer Stunde Ausfall pro Jahr, ist vor allem eine kommerzielle Absicherung des Anbieters. Eine technische Garantie für den Kunden steckt darin nicht. Wenn umsatzkritische Prozesse 15 Stunden stillstehen, helfen Gutschriften auf die Rechnung des Folgemonats wenig.
Am schwersten zu fassen ist das Risiko in der Trennung von Datenebene und Steuerungsebene. Die Datenebene transportiert den eigentlichen Verkehr und führt die Workloads aus. Die Steuerungsebene verwaltet, skaliert und konfiguriert die Ressourcen. Hyperscaler bauen ihre Systeme nach dem Prinzip der Static Stability: Die Datenebene soll auch dann weiterlaufen, wenn die Steuerungsebene ausfällt. Laufende VMs bleiben also meist erreichbar, selbst wenn das Verwaltungsportal ausgefallen ist.
Kritisch wird es im Moment der Veränderung. Muss ein System genau jetzt auf eine Lastspitze reagieren und fordern die Auto-Scaling-Gruppen neue Instanzen an, scheitert das, weil die zuständige Control Plane nicht antwortet. Geplante Failover, die im Fehlerfall DNS-Einträge umschreiben, neue Load-Balancer-Regeln setzen oder IP-Adressen umschwenken sollen, laufen ins Leere, denn das System, das die Änderung durchführen müsste, ist selbst gestört. Klassische Hochverfügbarkeit setzt voraus, dass die Steuerungsebene erreichbar bleibt. Bei großflächigen Cloud-Störungen ist genau diese Voraussetzung nicht mehr gegeben.
Business Impact statt Technikdebatte: Was fällt wirklich aus?
Das Bundesamt für Sicherheit in der Informationstechnik (BSI) gibt mit dem BSI-Standard 200-4 zum Business Continuity Management eine praxisnahe Methodik vor, um Ausfallsicherheit strukturiert zu planen und Notfallhandbücher aufzubauen.
Die Leitfrage verschiebt sich vom einzelnen ausgefallenen Server zur Geschäftsebene: Welche wertschöpfenden Prozesse stehen nach 15, 30, 60 und 240 Minuten still, und was kostet das?
Diese Frage beantwortet eine Business Impact Analyse (BIA). Sie identifiziert die kritischen Prozesse, die tolerierbaren Ausfallzeiten und die IT-Bausteine dahinter. Wer noch eine BIA aus On-Premises-Zeiten nutzt, sollte sie dringend um SaaS- und Hyperscaler-Abhängigkeiten erweitern. Die betriebswirtschaftlichen Folgen eines Ausfalls lassen sich in mehrere Kategorien sortieren.
| Impact-Kategorie | Geschäftliche Folgen bei einem Hyperscaler-Ausfall |
| Umsatzverlust | Sofort messbarer Schaden durch stillstehende Shops, blockierte Zahlungen oder gesperrte Buchungssysteme. |
| Lieferfähigkeit & Supply Chain | Logistik- und Lieferprozesse reißen ab. |
| Kundenservice & Betreuung | Callcenter arbeiten blind, sobald das cloudbasierte CRM ausfällt. Chatbots und Ticketsysteme (oft reine SaaS-Lösungen) fallen aus. Die Kundenzufriedenheit sinkt, Abwanderung droht. |
| Compliance & Meldepflichten | Gesetzliche Fristen geraten in Gefahr. Das NIS-2-Umsetzungsgesetz verlangt eine Frühwarnung ans BSI binnen 24 Stunden. Stehen die SIEM- und Analysesysteme still, lässt sich diese Pflicht kaum erfüllen. Bußgelder drohen. |
| Interne Produktivität | Fallen zentrale Kommunikationsmittel und der SSO-Dienst aus, können tausende Beschäftigte stundenlang nicht arbeiten. |
| Reputations- und Markenschaden | Schwer messbarer, langfristiger Vertrauensverlust. Die weltweite Berichterstattung über große Ausfälle beschädigt das Image nachhaltig. |
Tabelle: Kategorien einer Business-Impact-Analyse
Für jeden Kernprozess muss das Management zwei Kennzahlen festlegen: die maximal tolerierbare Ausfallzeit (Recovery Time Objective, RTO) und den maximal tolerierbaren Datenverlust rückwärts gerechnet (Recovery Point Objective, RPO).
Ein Beispiel: Setzt der Vorstand für die Logistik ein RTO von vier Stunden an, der zugrundeliegende Anbieter braucht im globalen Störungsfall aber — wie AWS im Oktober — bis zu 15 Stunden zur Wiederherstellung, klafft eine Lücke, die niemand akzeptieren kann. Genau solche Diskrepanzen aufzudecken und in geübte Continuity-Pläne nach BSI 200-4 zu überführen, ist der erste konkrete Schritt zu echter Resilienz.
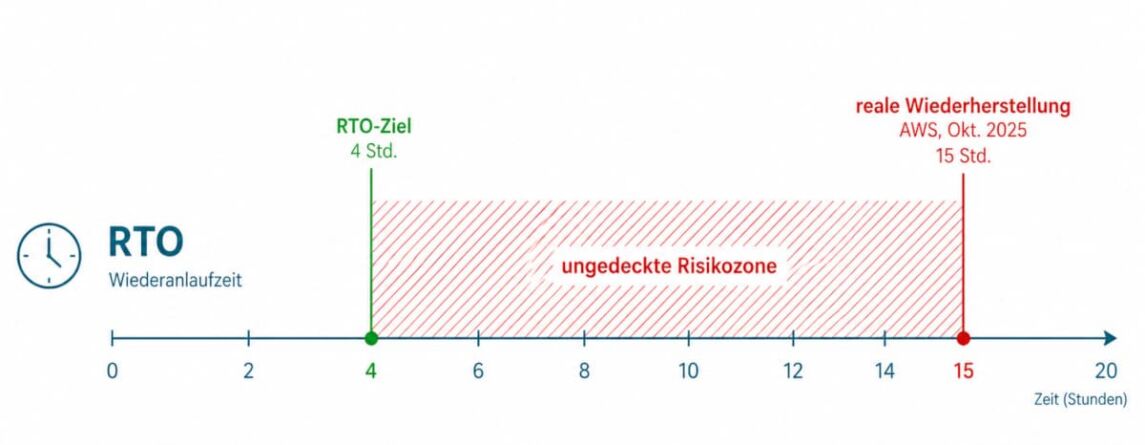
Abbildung: RTO: Ziel, tatsächliche Wiederherstellung und Risikozone
Resilienz-Check: Die wichtigsten Fragen für IT-Verantwortliche
Die Strategie aus BIA und BCM muss im Alltag ankommen, und das verlangt eine ehrliche Bestandsaufnahme. Die folgenden Fragen sollte jedes IT-Führungsteam ohne lange Vorbereitung beantworten können. Sie stammen direkt aus den Lehren der Oktober-Ausfälle und aus den Empfehlungen der Sicherheitsbehörden.
Erstens: die Landkarte der Abhängigkeiten
Welche kritischen Dienste hängen an welchem Anbieter, in welcher Region, an welchem globalen Dienst? Zu wissen, dass die Kundendatenbank bei Anbieter A in Frankfurt liegt, reicht nicht. Liegt das CDN, das den weltweiten Zugriff vermittelt, auch dort? Ist der vorgeschaltete DNS-Dienst regional isoliert oder ein global verwalteter Dienst wie Route 53 oder Azure Front Door, der zum Single Point of Failure wird?
Zweitens: Lesen und Schreiben im Notfall
Welche Systeme müssen jederzeit konsistent schreiben können: Finanztransaktionen, Inventarbuchungen etc, und für welche reicht es im Krisenfall, nur zu lesen, etwa Produktkataloge oder Wissensdatenbanken? Diese Unterscheidung erlaubt abgestufte Notbetriebe (Graceful Degradation): Statt komplett auszufallen, wechselt das System in einen reduzierten, stabilen Modus.
Drittens: Funktionieren Admin-Logins, Konsolen und hochprivilegierte Break-Glass-Konten auch dann noch, wenn der globale Identitätsdienst komplett offline ist?
Antwortet Entra ID oder der Cloud-SSO nicht, brauchen Administratoren lokal authentifizierte Hintertüren, um Kernsysteme zu steuern oder Failover von Hand auszulösen. Die US-Behörde CISA warnt seit Jahren vor Single Points of Failure bei der Cloud-Authentifizierung und empfiehlt gehärtete Zugänge mit robuster Mehr-Faktor-Authentifizierung, die im Notfall greift, ohne von den ausgefallenen Systemen abhängig zu sein.
Viertens: die Kommunikationsfähigkeit der Krisenteams
Können SecOps, DevOps, Krisenstab und Management überhaupt miteinander kommunizieren und Logs austauschen, wenn Chat, Cloud-E-Mail und Ticketsystem selbst betroffen sind? Wenn die gesamte interne Kommunikation über den ausfallenden Anbieter läuft, ist das Krisenmanagement von der ersten Minute an gelähmt.
Fünftens: die Notfallpläne
Gibt es getestete Schritt-für-Schritt-Anweisungen für den Ausfall von Cloud-, SaaS-, DNS- und Identitätsdiensten? Das BSI fordert versionierte, zentral bereitgestellte Continuity-Pläne. Liegen diese Pläne aber nur in genau dem SharePoint, das gerade weltweit nicht erreichbar ist, sind sie wertlos. Eine Offline-Kopie auf dedizierten Geräten ist Pflicht.
Sechstens: die Validierung
Wurde ein kompletter Failover in eine andere Region oder zu einem anderen Anbieter jemals unter echter Last getestet, oder existiert der Rettungsanker nur im Konzeptpapier? Erst regelmäßige, simulierte Ausfälle, das sogenannte Chaos Engineering, bringen versteckte Abhängigkeiten und Konfigurationsfehler ans Licht, bevor es im Ernstfall darauf ankommt.
Ist Multi-Cloud eine Lösung?
Ist es eine praktikable Lösung zur Streuung des Risikos, Workloads dauerhaft parallel über AWS, Azure und Google Cloud laufen zu lassen, um im Ernstfall nahtlos umschalten zu können?
Eine echte Active-Active-Spiegelung der gesamten Infrastruktur ist sehr teuer und technisch anspruchsvoll. Sie verdoppelt die Grundkosten für Compute und Storage und treibt vor allem die Egress-Kosten in die Höhe, weil die Datenbanken über die Clouds hinweg synchron bleiben müssen. Außerdem zwingt eine generische Multi-Cloud-Strategie die Entwickler auf den kleinsten gemeinsamen Nenner. Spezialisierte PaaS-Dienste (Platform as a Service), etwa für KI oder verwaltete Datenbanken, lassen sich kaum noch verwenden. Stattdessen läuft alles in standardisierten Kubernetes-Clustern, was einen großen Teil des Tempo- und Innovationsgewinns der Cloud wieder aufzehrt.
Auch organisatorisch ist der Anspruch hoch. IT-Teams müssen Sicherheitsrichtlinien, Compliance und Betrieb für mehrere unterschiedliche Ökosysteme parallel beherrschen. Angesichts des Fachkräftemangels ist das für die meisten Organisationen kaum zu leisten. In der Praxis verursachen Fehlkonfigurationen bei Rechten oder Netzfreigaben, die aus dieser Komplexität entstehen, häufiger Ausfälle als der Zusammenbruch eines Hyperscaler-Rechenzentrums.
Besser und praktikabler ist daher eine gezielte und risikobasierte Redundanz statt Multi-Cloud um jeden Preis. Für einzelne, besonders geschäftskritische Funktionen, die als Single Point of Failure erkannt sind, ergibt ein zweiter Anbieter durchaus Sinn, etwa unveränderliche Backups in einer separaten Cloud zur Isolierung gegen Ransomware, das primäre DNS-Routing über einen spezialisierten unabhängigen Dienst oder ein anbieterübergreifend redundant aufgestellter Identitätsdienst.
Für den Großteil der Standard-Workloads ist eine saubere Klassifizierung nach Kritikalität sinnvoller.
Checkliste für Entscheider
Die folgende Matrix dient der Audit-Vorbereitung. Sie richtet sich an CIOs, CISOs, IT-Leiter und Architekten.
| Residenz-Kategorie | Kritische Prüffrage für das IT-Management | Status / nächste Aktion |
| Kritische Geschäftsprozesse | Sind die Top-10-Prozesse (Umsatz, Logistik, Compliance) identifiziert, dokumentiert und vom Vorstand bestätigt? | ☐ Ja ☐ NeinBusiness Impact Analyse (BIA) starten |
| Abhängigkeits-Mapping | Gibt es eine aktuelle Architekturlandkarte mit allen transitiven Cloud-, SaaS-, Edge-, DNS- und Identity-Abhängigkeiten? | ☐ Ja ☐ NeinDeep-Dive-Mapping und Code-Review anordnen |
| Kontinuitäts-Kennzahlen | Sind RTO und RPO je Prozess definiert und mit den tatsächlichen Provider-SLAs abgeglichen? | ☐ Ja ☐ NeinMetriken validieren, SLA-Lücken ans Risikomanagement melden |
| Operative Validierung | Wurde der Failover auf Notfallsysteme im letzten Jahr unter Last physisch getestet? | ☐ Ja ☐ NeinChaos-Engineering-Test fürs nächste Quartal planen |
| Notfall-Zugriff (IAM) | Gibt es Break-Glass-Konten, per Hardware-MFA gesichert und nachweislich unabhängig vom primären Identity-Provider? | ☐ Ja ☐ NeinNotfallkonten nach CISA-Vorgaben härten und isolieren |
| Krisenkommunikation | Existieren Out-of-Band-Kanäle (Chat, Telefonie), die auch beim Ausfall von Diensten wie M365 autark laufen? | ☐ Ja ☐ NeinUnabhängige Kommunikationsalternative ausrollen |
| Digitale Souveränität | Werden Lieferantenrisiken und Lokalisierung systematisch nach den BSI-C3A-Kriterien bewertet? | ☐ Ja ☐ NeinVerträge auf C3A-Konformität und Exit-Strategien prüfen |
| Regulatorische Meldepflichten | Sind Prozesse etabliert, um die 24-Stunden-Meldepflicht nach NIS-2 ans BSI fristgerecht zu erfüllen? | ☐ Ja ☐ NeinMeldewege im Incident-Response-Plan fixieren |
| Strategische Budgetierung | Wird das Resilienz-Budget nach dem finanziellen Business Impact priorisiert? | ☐ Ja ☐ NeinMittel vom Gießkannenprinzip auf Risikobasis umstellen |
Tabelle: Cloud-Resilienz-Audit: Checkliste für Entscheider zur Vorbereitung
Diese Matrix gehört fest in den Rhythmus von IT-Governance, Vorstandsbericht und Risiko-Audit.
Häufige Fragen (FAQ)
Können wir uns gegen Hyperscaler-Ausfälle überhaupt absichern?
Vollständig verhindern lässt sich ein globaler Ausfall nicht. Begrenzen lässt sich aber, welchen Schaden er im eigenen Unternehmen verursacht. Wer seine Abhängigkeiten kennt, Notfallzugänge und einen zweiten Kommunikationsweg bereithält und den Wiederanlauf geübt hat, übersteht eine Störung mit deutlich weniger Schaden als ein Unternehmen, das erst im Ernstfall merkt, wie viel an einem einzigen Dienst hängt.
Schützt uns eine Multi-Region-Architektur vor solchen Ausfällen?
Teilweise. Multi-Region schützt gut gegen Probleme, die auf eine Region begrenzt sind. Gegen Fehler in global wirkenden Diensten wie DNS, einem zentralen Identitätsdienst oder der Edge-Schicht hilft es nicht automatisch; genau diese trafen 2025 die Unternehmen quer über alle Regionen.
Brauchen wir jetzt zwingend Multi-Cloud?
Für die meisten Unternehmen lautet die Antwort: nicht flächendeckend. Eine vollständige Active-Active-Spiegelung ist teuer, komplex und bindet rare Fachkräfte. Sinnvoll ist ein zweiter Anbieter gezielt für einzelne Single Points of Failure, etwa für unveränderliche Backups, DNS oder den Identitätsdienst. Für die übrigen Workloads empfiehlt sich meist eine saubere Multi-Region-Architektur bei einem Hauptanbieter.
Was sind Break-Glass-Konten, und warum sind sie so wichtig?
Break-Glass-Konten sind hochprivilegierte Notfallzugänge, die unabhängig vom normalen Cloud-Login funktionieren. Fällt der zentrale Identitätsdienst aus, kommt ohne sie niemand mehr in die Systeme, um Gegenmaßnahmen zu starten. Sie gehören mit Hardware-MFA gesichert, streng überwacht und regelmäßig getestet.
Wie finden wir heraus, welche versteckten Abhängigkeiten wir haben?
Über ein Dependency Mapping, das über die reine Serverliste hinausgeht. Erfassen Sie für jeden kritischen Prozess, welche Identitäts-, DNS-, CDN-, Zertifikats- und Monitoring-Dienste daran hängen und auf welchem Hyperscaler die genutzten SaaS-Anbieter selbst laufen. Ein Chaos-Engineering-Test deckt zusätzlich auf, was in der Theorie übersehen wurde.
Bekommen wir bei einem SLA-Verstoß unseren Schaden ersetzt?
In aller Regel nicht in voller Höhe. SLAs sehen meist Gutschriften vor, die in keinem Verhältnis zum tatsächlichen Geschäftsschaden stehen. Achten Sie in Verträgen deshalb stärker auf Reaktionszeiten, Kommunikationspflichten und Exit-Optionen als auf die reine Verfügbarkeit. Eine Rechtsberatung kann im Einzelfall ratsam sein.
Welche Meldepflichten gelten bei einem großflächigen Ausfall?
Für Unternehmen im Anwendungsbereich von NIS-2 sowie für KRITIS-Betreiber gelten kurze Fristen: eine Frühwarnung ans BSI binnen 24 Stunden nach Kenntnis eines erheblichen Vorfalls, gefolgt von ausführlicheren Meldungen. Die genauen Pflichten hängen vom Status des Unternehmens ab; eine Prüfung der eigenen Einstufung gehört in den Incident-Response-Plan.
Was ist der erste Schritt, wenn wir bisher kaum etwas vorbereitet haben?
Beginnen Sie mit einer Business Impact Analyse für die zehn wichtigsten Prozesse und einer ehrlichen Abhängigkeits-Landkarte. Allein das zeigt meist schon die größten Lücken: fehlende Notfallzugänge, ein einziger Kommunikationskanal, ungetestete Failover. Diese drei Punkte zuerst zu schließen, bringt im Verhältnis zum Aufwand den größten Sicherheitsgewinn.
Hardware-Lebenszyklus sicher und kosteneffizient verlängern
Weitere Artikel

Drittwartung vs. Hersteller-SLA: Praxisvergleich an Dell PowerEdge
Ein Dell PowerEdge der 14. oder 15. Generation hält leicht sieben bis zehn Jahre durch. Für File-Services, Active Directory, sekundäre

SpaceX 1,75 Billionen IPO-Wette und 10000 Sicherheitslücken dank Claude Mythos
Shownotes Die große These Die KI-Branche entscheidet sich gerade nicht mehr an den besten Modellen, sondern an den

Berlin, Frankfurt oder München: Wo lohnt sich Co-Location in Rechenzentren noch?
Die RZ-Standorte Frankfurt, Berlin / Brandenburg und München halten für Co-Location verschiedene Stärken und Schwächen bereit. Wer derzeit auf dem
