


Große Sprachmodelle (LLMs) scheitern dann, wenn zum Lösen einer Aufgabe echte physikalische Erfahrungen nötig sind. Dann kommen World Models ins Spiel. Wir beschreiben die Unterschiede zwischen den Ansätzen und für welche Aufgaben sie sich eignen.
Wie die KI lernt, die Welt zu verstehen
Bis heute bestimmen vor allem LLMs die Schlagzeilen, von den ersten Chatbots bis zu den heutigen Frontier-Modellen. In der Forschung wächst aber der Zweifel an der Annahme, dass ein Sprachmodell allein durch mehr Parameter und mehr Trainingsdaten irgendwann zu einer echten, allgemeinen Intelligenz (Artificial General Intelligence, AGI) heranreift. Die sogenannte Skalierungshypothese gerät zunehmend unter Druck.
Am lautesten widerspricht Yann LeCun, Turing-Preisträger und einer der weltweit führenden KI-Vordenker. Für ihn sind reine Sprachmodelle eine Sackgasse auf dem Weg zur AGI. Sein Argument: Ein System, das nur Text gesehen hat, kennt die physische Welt nicht. Es kann Schwerkraft, Wärmelehre oder die Geometrie eines Raums grammatikalisch einwandfrei beschreiben und hat trotzdem nie erlebt, wie etwas fällt, heiß wird oder im Weg steht.

Abbildung: Eine Tasse fällt zu Boden – kurz vor dem Aufprall
Sprache ist aus Sicht der Informationstheorie stark verdichtet. Sie funktioniert nur, weil Sprecher und Zuhörer enorm viel ungesagtes Wissen über die Welt teilen. Tiere zeigen, dass Intelligenz auch ohne gesprochene Sprache aus Worten funktioniert: Ameisen, Bienen und Krähen navigieren, bauen Werkzeuge und lösen Probleme, und das alles ohne ein einziges gesprochenes Wort. Das deutet darauf hin, dass eine künstliche Intelligenz mit der echten, physischen Welt verbunden sein muss, wenn sie diese verstehen soll. Sprache ist dagegen eher ein Ergebnis von Intelligenz als ihre Quelle.
Weltmodelle (World Models) gehen einen anderen Weg. Sie lernen ein inneres Bild der Welt direkt aus vielen Sinnesquellen gleichzeitig: aus Bildern, Videos, Tönen, Bewegungen und aus dem, was bei physischem Kontakt passiert. LLMs sagen voraus, wie sich eine Situation im nächsten Moment entwickelt. Sie schätzen ab, wie sich Dinge bewegen, welche Kräfte wirken, wie Reibung und Stabilität ausfallen und wie Objekte im Raum zueinander stehen. So lernen sie die ungeschriebenen Gesetze der Physik. Damit verschiebt sich KI hin zur verkörperten KI, der sogenannten Embodied AI, die physisch mit der Welt umgehen und die Folgen ihres Handelns vorausberechnen kann.
2. Die wichtigsten Unterschiede zwischen LLMs und World Models
Wer technisch und strategisch entscheiden will, braucht ein Gespür für vier Unterschiede: die Zustandsverfolgung, den Umgang mit Fehlern, die Form der Daten und die nötige Hardware.
2.1 Offene Schleife (Open-loop) vs. geschlossene Schleife (Closed-loop)
LLMs arbeiten in einer offenen Schleife (open loop). Sie schauen auf die bisherige Folge von Token, das Kontextfenster, und berechnen daraus das wahrscheinlichste nächste Token. Das Problem steckt im Mechanismus selbst: Schreibt das Modell ein falsches oder erfundenes Token, landet dieses sofort in der eigenen Eingabe für den nächsten Schritt. Fehler bauen sich so auf und verstärken sich im Lauf der Antwort. Halluzinationen kann das Modell von innen heraus kaum erkennen, weil es keinen Weltzustand kennt, gegen den es seine Ausgabe prüfen könnte.
Weltmodelle dagegen führen einen inneren Zustand, der sich über die Zeit fortschreibt. Dieser latente Zustand ist so etwas wie der physische Anker des Systems. Er erlaubt eine geschlossene Schleife (closed loop): Weicht die Vorhersage, wie die Welt im nächsten Moment aussehen sollte, von dem ab, was die Sensoren tatsächlich melden, korrigiert das System sofort. Ein autonomes Fahrzeug sagt zum Beispiel laufend voraus, wo sich ein Fußgänger im nächsten Videobild befinden wird. Stimmt die Realität nicht mit der Vorhersage überein, passt das Modell seinen inneren Zustand umgehend an.
Genau diese Fähigkeit, den Zustand zu verfolgen und Fehler laufend zu korrigieren, ist überall dort gefragt, wo ein Abweichen teuer oder gefährlich wird: beim autonomen Fahren, in der Industrieautomatisierung oder bei robotergestützten Operationen. Verlässlich wird ein solches System dadurch, dass es sich sofort anhand seiner Sensoren korrigieren kann. Perfekte Vorhersagen braucht es dafür nicht.
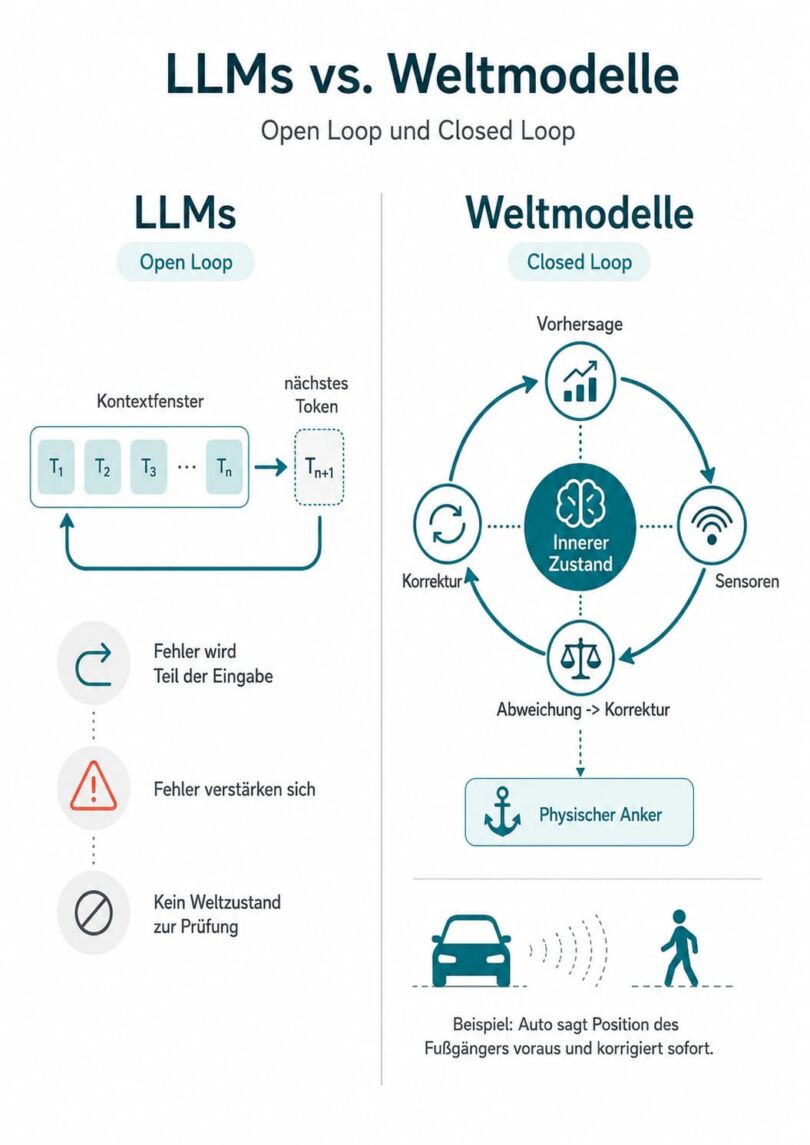
Abbildung: LLMs vs. World Models: Open vs. Closed Loop
2.2 Pixel-Rekonstruktion vs. abstrakter latenter Raum
Frühe generative World Models versuchten, die Welt Bildpunkt für Bildpunkt vorherzusagen. Das frisst Rechenleistung für Details, die niemanden interessieren: das zufällige Flackern von Blättern im Wind oder die genaue Struktur einer Wasseroberfläche. Das Ergebnis war ineffizient und verallgemeinerte schlecht.
Moderne Weltmodelle drehen den Spieß um und arbeiten im latenten Raum. Metas Joint Embedding Predictive Architecture (JEPA) zeigt das gut. Modelle wie V-JEPA für Video oder I-JEPA für Bilder verzichten beim Training ganz auf die Pixelrekonstruktion. Stattdessen sagen sie fehlende oder künftige Inhalte in einer abstrakten Darstellung voraus.
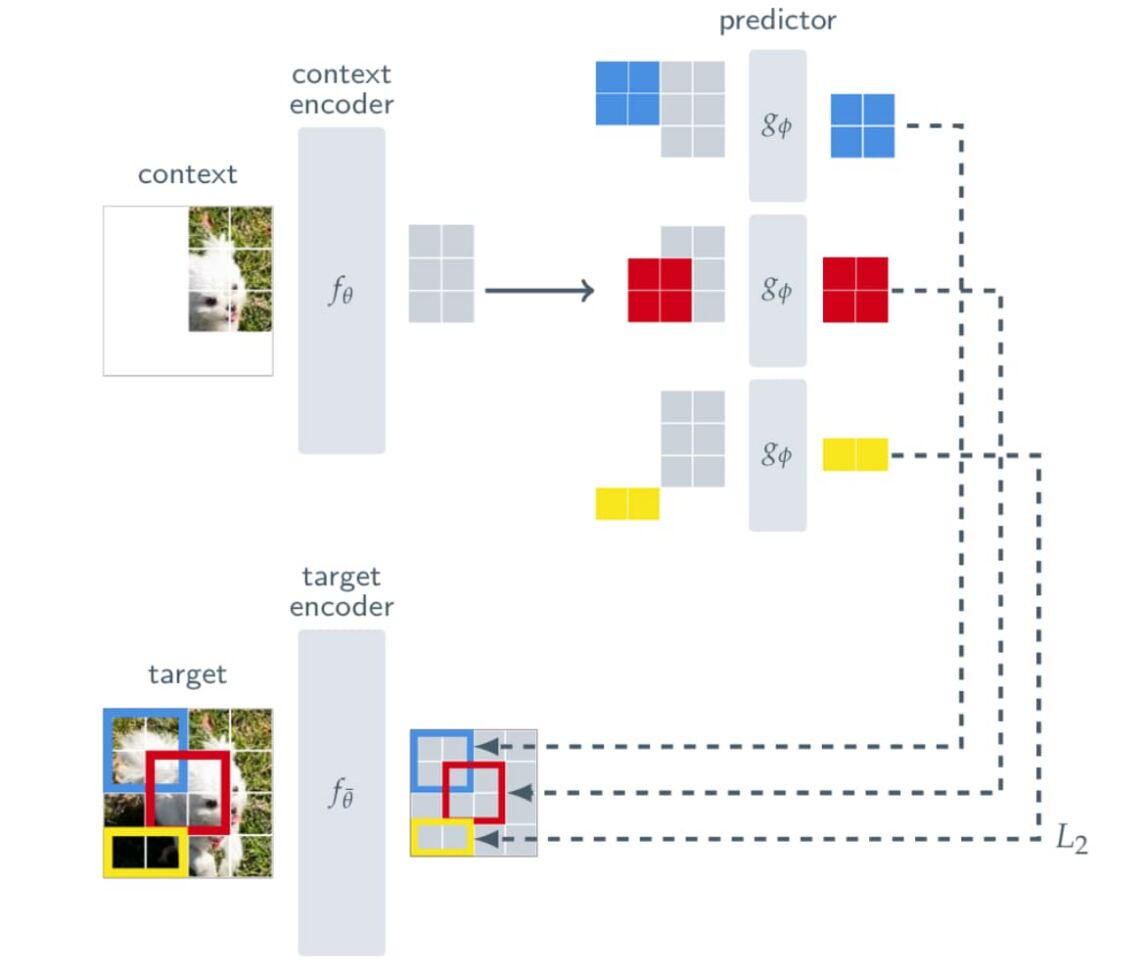
Abbildung: Funktionsweise von I-JEPA. Quelle: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran, Yann LeCun et. al.
Das System schaut sich einen bekannten Ausschnitt eines Bildes an (den Kontext) und versucht daraus zu berechnen, welche Informationen in anderen, verdeckten Teilen desselben Bildes (den Zielen) stecken müssten. Der Beobachter (Context Encoder) ist ein Programm, das sich ausschließlich die sichtbaren Bildausschnitte ansieht und diese analysiert. Der Vorhersager (Predictor) ist ein zweites, etwas simpleres Programm. Es verwendet das gesammelte Wissen des Beobachters. Wenn man ihm nun sagt, wo genau im Bild ein Stück fehlt (die positionalen Token), versucht es, den Inhalt dieses fehlenden Puzzleteils mathematisch vorherzusagen.
Um zu prüfen, ob die Vorhersage richtig war, liefert der Target Encoder das „echte“ Ergebnis für den fehlenden Teil. Dieses Kontrollprogramm lernt nicht völlig eigenständig, sondern schaut sich schrittweise und fließend die Fähigkeiten vom „Beobachter“ ab.
Weil das Pixel-Decoding wegfällt, lassen sich Modelle wie V-JEPA sehr effizient und selbstüberwacht auf riesigen Datensätzen wie VideoMix2M trainieren. Sie lernen Bewegungen und Kräfte auf einer begrifflichen Ebene zu erfassen, ohne sich an optischen Kleinigkeiten zu verschlucken. V-JEPA ist außerdem das erste Videomodell, bei dem „Frozen Evaluations“ funktionieren: Der Kern des Modells bleibt eingefroren, und für eine neue Aufgabe genügt eine kleine zusätzliche Schicht obendrauf. Für die Robotik ist das ein großer Effizienzgewinn.
2.3 Hardware und Rechenleistung
Ein Unterschied zwischen LLMs und World Models, der in der Debatte oft untergeht, in der Praxis aber den Ausschlag gibt, betrifft den Anspruch an Hardware und Recheninfrastruktur.
Das Training von LLMs lebt von riesigen Matrixmultiplikationen auf GPU-Clustern wie NVIDIA H100 oder B200 mit hohem Speicherdurchsatz für die Textmengen. Weltmodelle brauchen mehr. Neben klassischen Tensorkernen für das Deep Learning verlangen sie Rechenkraft für physikalische Simulation und für das Rendern ganzer Umgebungen. Physikalische KI entsteht mit Physik-Engines für starre Körper (etwa PhysX) und mit Raytracing-Clustern, die synthetische Trainingsdaten in physikalisch korrekten Simulatoren wie NVIDIA Omniverse oder Isaac Sim in Echtzeit berechnen.
Auch die Datenmengen explodieren. Ein Textkorpus misst sich in Terabyte; synthetische Videodatensätze für Weltmodelle wie das SDG-Warehouse-Dataset erreichen schnell Dutzende bis Hunderte Terabyte an unkomprimiertem, hochauflösendem Video. Dazu kommen pixelgenaue Tiefen- und Segmentierungskarten. Das verlangt spezielle Speichersysteme, sehr schnelle Netze wie Infiniband und einen deutlich höheren Aufwand bei Wartung und Kühlung, denn die laufenden Rendering-Pipelines belasten die GPUs thermisch anders als die abgehackten Text-Batches.
2.4 Der Vergleich zwischen LLMs und World Models auf einen Blick
Die folgende Tabelle stellt die wichtigsten Unterschiede zwischen LLMs und World Models nebeneinander.
| Architektonische Dimension | Large Language Models (LLMs) | World Models |
| Primäres Lernziel | Nächstes Token vorhersagen (autoregressiv) | Den künftigen Systemzustand vorhersagen |
| Datenbasis | Überwiegend Text, Code, einzelne Bilder | Viele Sinnesquellen: Video, Audio, Bewegung, Physik, Aktionen |
| Absicherung in der Realität | Keine eingebaute physische Erdung (Grounding) | Stark, verankert in physikalischen Gesetzen |
| Kontrollschleife | Offen (anfällig für sich aufschaukelnde Halluzinationen) | Geschlossen, mit ausdrücklichem State Tracking und Korrektur |
| Planungshorizont | Diskret, symbolisch, über Sprache vermittelt | Kontinuierlich, räumlich-zeitlich, physikalisch |
| Hardware-Fokus | Viel schneller Speicher für große Textkontexte | Physik-Engines, Rendering, hohe Speicherbandbreite für Videos |
3. Wann LLMs der passende Ansatz sind
Trotz aller Kritik bleiben LLMs für viele Aufgaben die beste und mit Abstand günstigste Lösung. Ihre Stärke zeigt sich überall dort, wo ein Problem auf Information, Symbolen oder Bedeutung beruht und keine direkte Manipulation der physischen Welt verlangt.
3.1 Sprache verarbeiten, Code schreiben, Wissen abrufen
LLMs verdichten große Mengen unstrukturierten Textwissens und fügen sie neu zusammen. Bei Chatbots, beim Programmieren, beim Übersetzen, beim Zusammenfassen von Dokumenten und beim Beantworten von Fachfragen sind aktuelle Spitzenmodelle wie Opus 4.8 von Anthropic oder Gemini 3.5 Flash von Google kaum zu schlagen. Sie wurden gezielt auf Agenten-Workflows, das Befolgen von Anweisungen und den Abruf von Wissen in Echtzeit (Retrieval-Augmented Generation, RAG) ausgerichtet. Sie bedienen Software, rufen APIs auf und ziehen logische Schlüsse im Raum der Sprache.
Für ein Python-Skript oder ein juristisches Gutachten wäre ein physikalisches Weltmodell überdimensioniert, weil sich diese Aufgaben über die statistische Verteilung von Symbolen schon sehr gut abbilden lassen.
3.2 Muster in wissenschaftlichen und symbolischen Daten erkennen
Spannend wird es bei wissenschaftlichen Daten, die sich wie Sprache verhalten. Weil LLM-artige Transformer darin geübt sind, versteckte Muster in langen Folgen zu finden, eignen sie sich für Felder mit sequenzartiger Struktur, etwa DNA-Sequenzen, Proteinfaltung oder Zeitreihen.
Ein Beispiel von Google DeepMind macht das greifbar: Eine auf LLM-Prinzipien und Baumsuche gebaute Architektur fand 40 neue Methoden, um Daten einzelner Zellen in der Bioinformatik auszuwerten, und schlug damit von Menschen entwickelte Spitzenverfahren auf öffentlichen Bestenlisten.
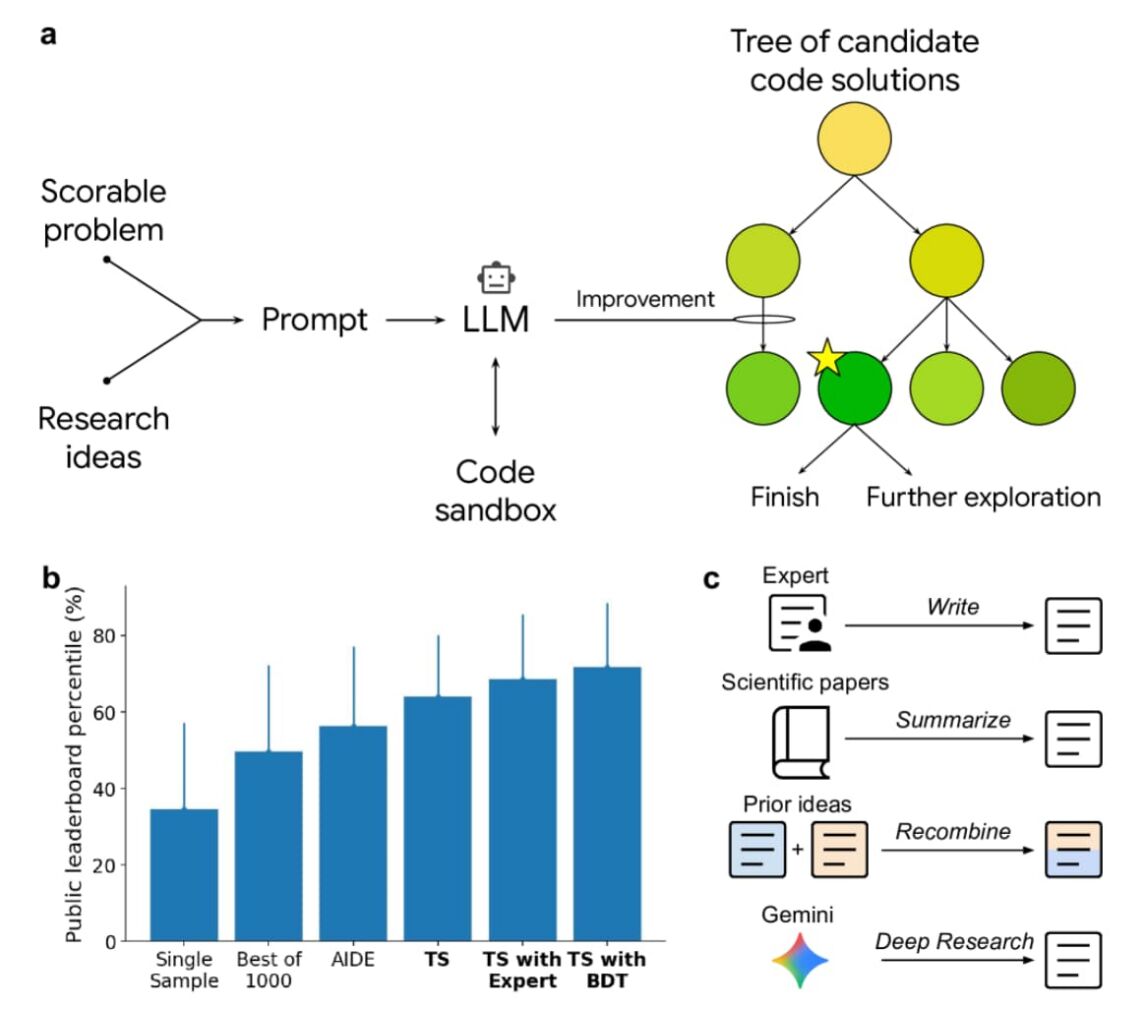
Abbildung: Auswahl von Methoden-Kandidaten zur Codegenerierung per LLM und Baumsuche. Quelle: An AI system to help scientists write expert-level empirical software, Google DeepMind
a: Eine bewertbare Aufgabe wird zusammen mit Forschungsideen, die Methoden zur Lösung dieser Aufgabe vorschlagen, in ein LLM eingespeist. Dieses generiert Code, um die bewertbare Aufgabe in einer Sandbox auszuwerten. Dies wird anschließend in einen Algorithmus zur Baumsuche eingebettet. Neue Knoten werden durch Sampling aus dem LLM ausgewählt.
b: Leistung von Methoden zur Codegenerierung beim Kaggle Playground-Benchmark. Die Ergebnisse zeigen die durchschnittliche Perzentil-Leistung auf dem öffentlichen Leaderboard über 16 Aufgaben hinweg.
c: Mechanismen zur Erstellung initialer Forschungsideen für die Lösung wissenschaftlicher Probleme.
In der Epidemiologie erzeugten dieselben Modelle 14 Vorhersagemodelle für COVID-19-Klinikeinweisungen, die etablierte Modelle der US-Gesundheitsbehörde CDC übertrafen.
Auch bei der Vorhersage neuronaler Aktivität in Zebrafischen, bei Finanzzeitreihen und beim numerischen Lösen schwieriger Integrale lieferten solche Modelle Spitzenergebnisse. Sobald ein Problem rein digital ist und einer mathematisch-statistischen Folge gleicht, hat der LLM-Ansatz die Nase vorn.
3.3 Grobplanung und Alltagswissen in Agentensystemen
In KI-Agentensystemen eignet sich ein LLM hervorragend als Planer auf oberster Ebene. Eine vage Anweisung wie „Räum die Küche auf“ zerlegt es dank seines riesigen Vortrainings in eine sinnvolle Abfolge von Teilzielen, etwa: Schwamm suchen, Schwamm anfeuchten, Tisch abwischen. Es bringt ein breites, aus Texten gelerntes Alltagswissen mit, etwa dass zerbrechliches Geschirr vorsichtig abgestellt werden muss oder dass manche Arbeitsschritte in einer bestimmten Reihenfolge ablaufen müssen. Für diese Art von Grobplanung und für das Gespräch mit Menschen in natürlicher Sprache sind LLMs wie geschaffen.
4. Wann World Models der passende Ansatz sind
Weltmodelle sind notwendig, sobald eine KI die digitale Welt verlässt und selbst physisch handeln muss – die sogenannte Embodied AI, zu der beispielsweise Roboter zählen. Der Grund: Die Welt folgt physikalischen Konstanten, räumlichen Formen, Kräften und strengen Ursache-Wirkungs-Ketten, die sich in reinem Text nicht ausreichend darstellen lassen.
4.1 Räumliche Intelligenz und Simulation
Spatial Intelligence, also räumliche Intelligenz, ist die Fähigkeit, Sehen in Handeln und visuelles Verstehen in räumliches Schlussfolgern zu übersetzen. Vorangetrieben wird das Konzept von der KI-Pionierin Fei-Fei Li und ihrem Unternehmen World Labs. Modelle wie Marble von World Labs oder die „Genie“-Reihe von Google DeepMind sind dafür gebaut, interaktive 3D-Welten aufzubauen, zu erzeugen und durchzuspielen.
Genie 3 bedeutet in diesem Zusammenhang einen großen Sprung. Es ist das erste interaktive Weltmodell, das in Echtzeit fotorealistische Welten aus einer einfachen Textbeschreibung erzeugen kann. Agenten können diese Welten erkunden und darin die Folgen ihrer Handlungen üben. Das Modell merkt sich frühere Aktionen, bildet komplexe physikalische Eigenschaften wie das Strömen von Wasser ab und verarbeitet, wie dreidimensionale Objekte aufeinander wirken.

Für das Training von Robotern ist das Gold wert: In der erzeugten Welt, also im „Traum“ der KI, kann ein Roboter gefahrlos Millionen Versuche durchlaufen und aus Fehlern lernen.
4.2 Autonomes Fahren in unstrukturierten Umgebungen
Das autonome Fahren ist ein besonders anspruchsvolles Feld für Weltmodelle. Klassische regelbasierte Systeme und auch reine Vision-Language-Modelle scheitern oft an der Unordnung echter Straßen. Ein LLM, das Autofahren nur über Texte zu Verkehrsregeln gelernt hat, begreift die physische Lage zu langsam, um in Sekundenbruchteilen eine Vollbremsung auszulösen.
Das britische Unternehmen Wayve zeigt, warum generative Weltmodelle hier vorne liegen. Wayve trainiert Modelle, die direkt aus rohen Videodaten vorhersagen, wie sich eine Umgebung in den nächsten Sekunden verändert. Wie CEO Alex Kendall in einem Podcast beschreibt, entsteht dabei von selbst vorsichtiges Verhalten, etwa das langsame Herantasten an eine Abzweigung, die ein parkender Lkw verdeckt, weil das Modell eine kausale Erwartung an die Dynamik von Kreuzungen aufgebaut hat.
In dieselbe Richtung zeigt der Einsatz von DeepMinds Genie 3 bei Waymo. Das „Waymo World Model“ nutzt diese Architektur, um fotorealistische LiDAR-Daten (Light Detection and Ranging, also per Laser ermittelte Abstandsdaten) und Kameraperspektiven in vierfacher Echtzeitgeschwindigkeit zu simulieren. Aus Dashcam-Videos werden vollständig begehbare 3D-Welten, in denen Waymo seine Fahragenten auf extreme Wetterlagen und seltene Unfallszenarien vorbereitet, ohne die echte Flotte zu gefährden.
4.3 Robotik, Embodied AI und physische Manipulation
In der Robotik ist das „Action Knowledge“, also das Wissen über das Handeln, der entscheidende Faktor. Wie verwandelt ein humanoider Roboter den Satz „Räum den Tisch ab“ in ein sicheres Ergebnis? Hier zählen winzige Größen: die Drehmomentgrenzen der Servomotoren, die Reibung der Tischoberfläche und die genaue Form des Greifers sind nur einige der Kriterien.
Ein LLM kann die Flugbahn eines Balls oder das Greifen einer Tasse nur als umständliche Folge von Textbeschreibungen oder statischen Gleichungen behandeln. Ein Weltmodell dagegen speichert die Regeln der Physik direkt in großen Vektorfeldern aus Körpergefühl (Propriozeption), Sehen und Tasten. So leitet es ganz von selbst ab, dass ein hochgeworfener Ball wieder herunterkommt oder eine Tasse bei zu viel Druck zerbricht. Diese unmittelbare Verbindung zur Welt macht Weltmodelle zur einzigen tragfähigen Architektur für humanoide Roboter wie Tesla Optimus oder die Figure-Reihe, die im Alltag mit ständig neuen, unvorhergesehenen Aufgaben klarkommen müssen.
5. Woran man die passende Architektur erkennt
Ob LLM, Weltmodell oder eine Kombination der am besten geeignete Ansatz für ein Problem ist, hängt von mehreren Größen ab, die sich teils widersprechen. An ihnen entscheidet sich, ob ein Projekt sauber skaliert oder an physikalischen und informationstechnischen Grenzen scheitert.
Die folgende Tabelle stellt die wichtigsten Entscheidungsachsen gegenüber.
| Entscheidungsdimension | Indikator für LLM-Einsatz | Indikator für World-Model-Einsatz |
| Umgebungsdynamik | Statisch, regelbasiert, text- und logiklastig (Code, Mathematik, Dokumente) | Dynamisch, physikalisch durchgehend, unberechenbar (Straßenverkehr, Alltagssituationen) |
| Kausales Verständnis | Statistische Wortzusammenhänge genügen für den Fall | Echte physikalische Ursache und Wirkung, Kräfte und Objekteigenschaften sind gefragt |
| Fehlertoleranz | Fehler verkraftbar oder per „Human-in-the-Loop“ korrigierbar | Fehler haben kritische, sicherheitsrelevante Folgen; Korrektur in Echtzeit nötig |
| Latenz und Ausführung | Sekunden für die Token-Generierung sind in Ordnung | Echtzeit, Reaktion im Millisekundenbereich zwingend |
| Datenverfügbarkeit | Zugang zu Milliarden Textdokumenten und Code-Repositories | Zugang zu großen Video-, LiDAR- und Bewegungsdatensätzen |
| Hardware & Infrastruktur | Fokus auf VRAM für große Textkontexte und Inferenz | Physik-Engines, Omniverse-Simulationen, riesiger Video-Speicher |
6. Hybride Architekturen: Sprache und Physik wachsen zusammen
Sehr erfolgversprechend ist derzeit ein dritter Weg: hybride Systeme, die das sprachliche und planerische Können der LLMs mit dem physikalischen Grounding und der genauen Zustandsverfolgung der Weltmodelle verbinden.
In einem solchen Aufbau plant ein LLM (oder ein visuelles Sprachmodell, VLM) die groben Schritte. Es erzeugt aus Sprache oder Bildern grobe Handlungskommandos und zerlegt eine Aufgabe in Teilziele. Das angeschlossene Weltmodell oder ein Simulator übernimmt die Feinarbeit: Es prüft die Kommandos gegen die Physik, sagt die Folgen voraus und steuert die Bewegung, bevor etwas Unumkehrbares in der echten Welt passiert.
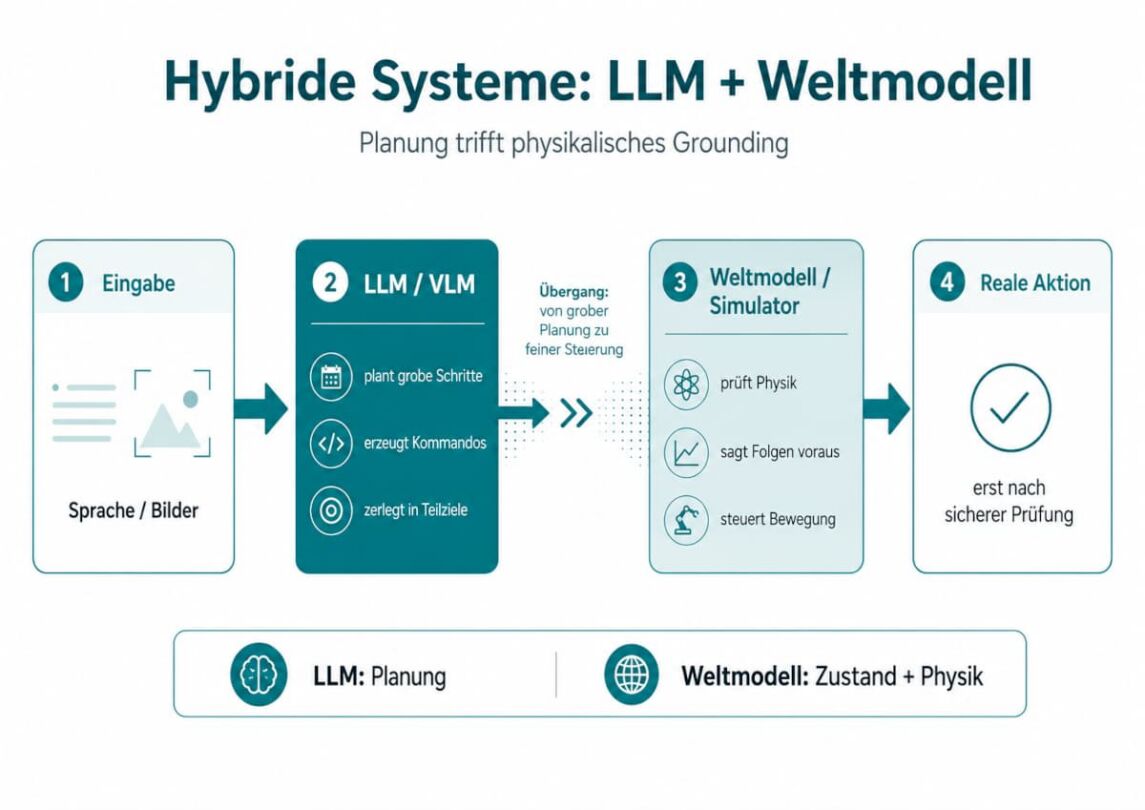
Abbildung: Hybride Systeme aus LLM und World Model
6.1 Das SayCan-Framework (Google)
Ein früher Meilenstein des Zusammenspiels zwischen LLM und World Model ist das SayCan-Projekt von Google Research. SayCan zeigte als Erstes, wie sich Sprachmodelle mit Milliarden Parametern in mobilen Manipulator-Robotern verankern lassen, im Fachjargon „Affordance Grounding“.

Abbildung: Google SayCan-Projekt: Ein Roboter räumt eine verschüttete Cola-Dose auf und macht sauber
Der Trick steckt in einer einfachen Wahrscheinlichkeitsrechnung. Das LLM schätzt, wie nützlich eine Fähigkeit (zum Beispiel „Dose greifen“) für eine Anweisung in natürlicher Sprache ist („Ich habe ein Getränk verschüttet, hilf mir“). Gleichzeitig liefert eine an das Weltmodell gekoppelte Wertfunktion (Affordance) die Wahrscheinlichkeit, dass sich diese Fähigkeit im aktuellen Zustand überhaupt ausführen lässt („Ist der Schwamm in Reichweite?“, „Ist der Weg frei?“). Das System multipliziert beide Werte und wählt Schritt für Schritt die Aktionen, die sprachlich sinnvoll und zugleich physikalisch machbar sind. So entschärft SayCan das sogenannte Moravec-Paradox, also die Beobachtung, dass abstraktes Denken für Maschinen leicht und einfache Bewegungen für sie schwer sind, durch eine clevere Arbeitsteilung. Siehe dazu auch das sehr anschauliche Erklärvideo von Google Research.
6.2 WorldVLM im autonomen Fahren
Ein weiteres Beispiel für die Zusammenarbeit zwischen LLM und World Model ist WorldVLM für das autonome Fahren, das an der Hochschule München entwickelt wurde. Hier plant ein Vision-Language-Modell (VLM) das Verhalten auf der oberen Ebene. Es liest komplexe Verkehrsszenen und gibt nachvollziehbare, situationsabhängige Empfehlungen („Weiche dem Fußgänger aus, der auf die Straße tritt“). Diese sprachlich begründete Einschätzung steuert dann ein schlankes latentes Weltmodell, das sich allein um die genaue, physikalische Vorhersage der eigenen Fahrlinie kümmert. So treffen die Erklärbarkeit und das Alltagswissen des LLMs auf die physikalische Verlässlichkeit und die Reaktionsschnelligkeit des Weltmodells, und die Lücke zwischen schöner Theorie und messbarer Fahrsicherheit schließt sich.
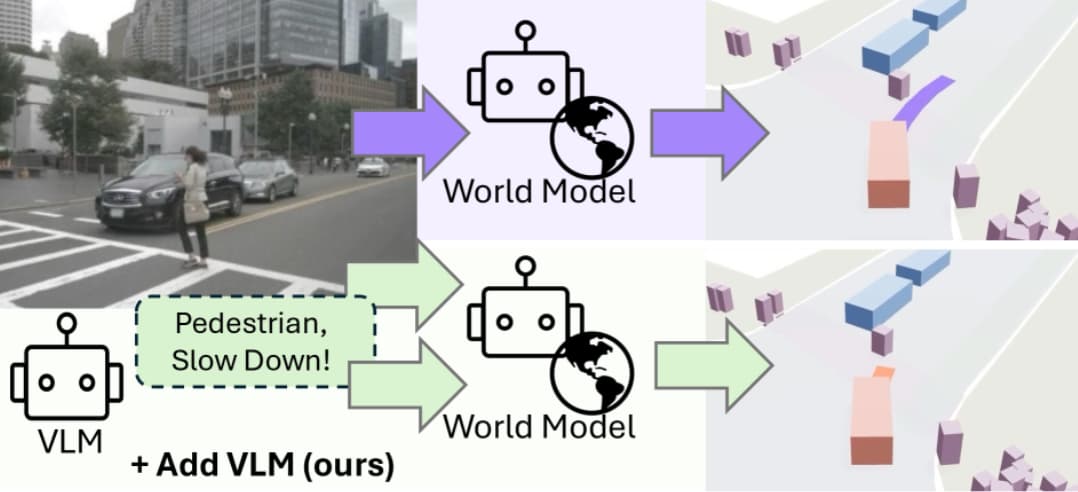
Abbildung: Beim WorldVLM für autonomes Fahren gibt das VLM in Abhängigkeit der Situation Empfehlungen, die dann vom World Model passend umgesetzt werden. Quelle: Hochschule München
6.3 NVIDIA Cosmos 3: Mixture-of-Transformers (MoT)
An der Spitze der hybriden Industriesysteme steht NVIDIA Cosmos 3, eine Familie omnimodaler Weltmodelle für physikalische KI. Cosmos 3 setzt auf eine Mixture-of-Transformers-Architektur (MoT), die das alte Problem getrennter Modalitäten (Text, Video, Aktion) auflöst. Das System besteht aus zwei spezialisierten Säulen (Towers):
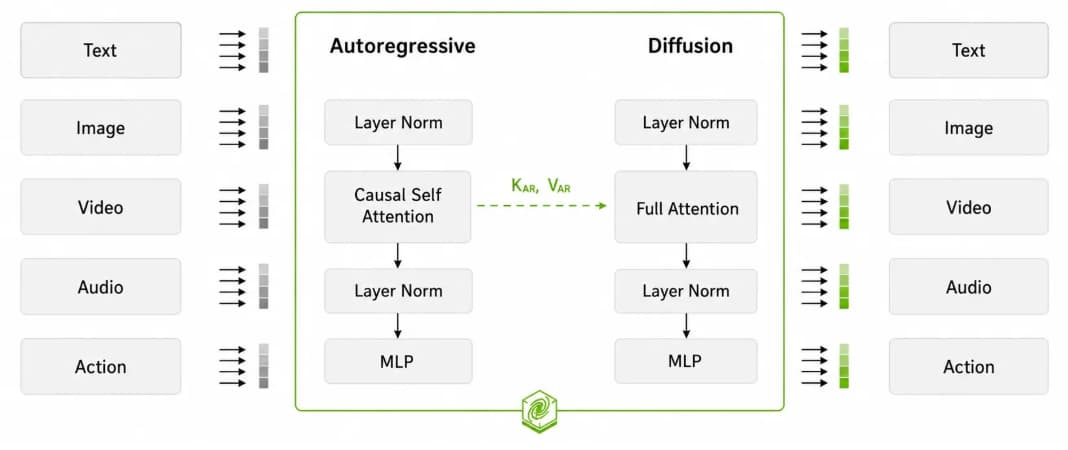
Abbildung: Architektur von Nvidia Cosmos 3
- Der Reasoner Tower (VLM): ein autoregressives Modell, das als kognitives „Gehirn“ arbeitet. Es verarbeitet Bilder, Video, Text und Audio und analysiert den physikalischen Kontext, die Bewegungsmuster und die Absichten der Akteure in einer Szene.
Der Generator Tower (Diffusion): ein diffusionsbasiertes Weltmodell, das physikalisch stimmige Video- oder Aktionsausgaben erzeugt. Es hängt eng an den Schlüssen des Reasoners und simuliert zum Beispiel seltene physikalische Sonderfälle in Echtzeit.

Abbildung: Nvidia Cosmos 3: Roboterhand greift Hammer und hängt ihn an die Wand
Damit lassen sich „World Action Models“ (WAMs) trainieren. Ein Industrieroboter bekommt Text, Video und Aktionen als Eingabe und liefert sowohl eine logische Textanalyse als auch eine physikalisch korrekte Videovorhersage seiner nächsten Handlung, etwa wie er ein zerbrechliches Objekt greift.
9. Ausblick: auf dem Weg zur AGI
Der Wechsel von rein sprachlichen LLMs hin zu physikalisch verankerten Weltmodellen ist der vielleicht wichtigste Schritt auf dem Weg zur allgemeinen künstlichen Intelligenz (AGI). Im Zentrum steht Yann LeCuns Idee der Autonomous Machine Intelligence (AMI).
LeCun beschreibt in seiner Forschung autonome Agenten, die sich nicht mehr durch starre Programmierung oder simple äußere Belohnungen steuern lassen wie beim klassischen Reinforcement Learning. Sie folgen inneren „Cost-Modulen“, die informationstheoretisch ähnlich wirken wie Gefühle bei Lebewesen: Neugier, das Vorfühlen auf Erfolg oder das Vermeiden von Schaden. Ein Weltmodell mit solchen Modulen bekommt einen Eigenantrieb, die Welt zu erkunden und seine Vorhersagen zu verbessern.
Das System setzt sich aus den folgenden Hauptkomponenten zusammen:
- Konfigurator (Configurator): Nimmt Eingaben von allen anderen Modulen entgegen und passt diese an die jeweils anstehende Aufgabe an.
- Wahrnehmung (Perception): Schätzt den aktuellen Zustand der Welt ab.
- Weltmodell (World model): Sagt mögliche zukünftige Zustände der Welt voraus, basierend auf Handlungssequenzen, die der Akteur (Actor) sich vorstellt.
- Kostenmodul (Cost): Berechnet die „Energie“, also das Maß an Unbehagen des Agenten. Es besteht aus zwei Untermodulen: den unveränderlichen intrinsischen Kosten (die direkte Reaktionen wie Schmerz oder Hunger messen) und dem trainierbaren Kritiker (Critic), der zukünftige intrinsische Kosten vorhersagt.
- Kurzzeitgedächtnis (Short-term memory): Speichert und verfolgt aktuelle sowie vorhergesagte Weltzustände und die damit verbundenen intrinsischen Kosten.
Akteur (Actor): Berechnet Vorschläge für Handlungssequenzen. Mithilfe des Weltmodells und des Kritikers wählt der Akteur die optimale Handlungssequenz aus, welche die geschätzten zukünftigen Kosten minimiert, und gibt die erste Aktion dieser Sequenz aus.
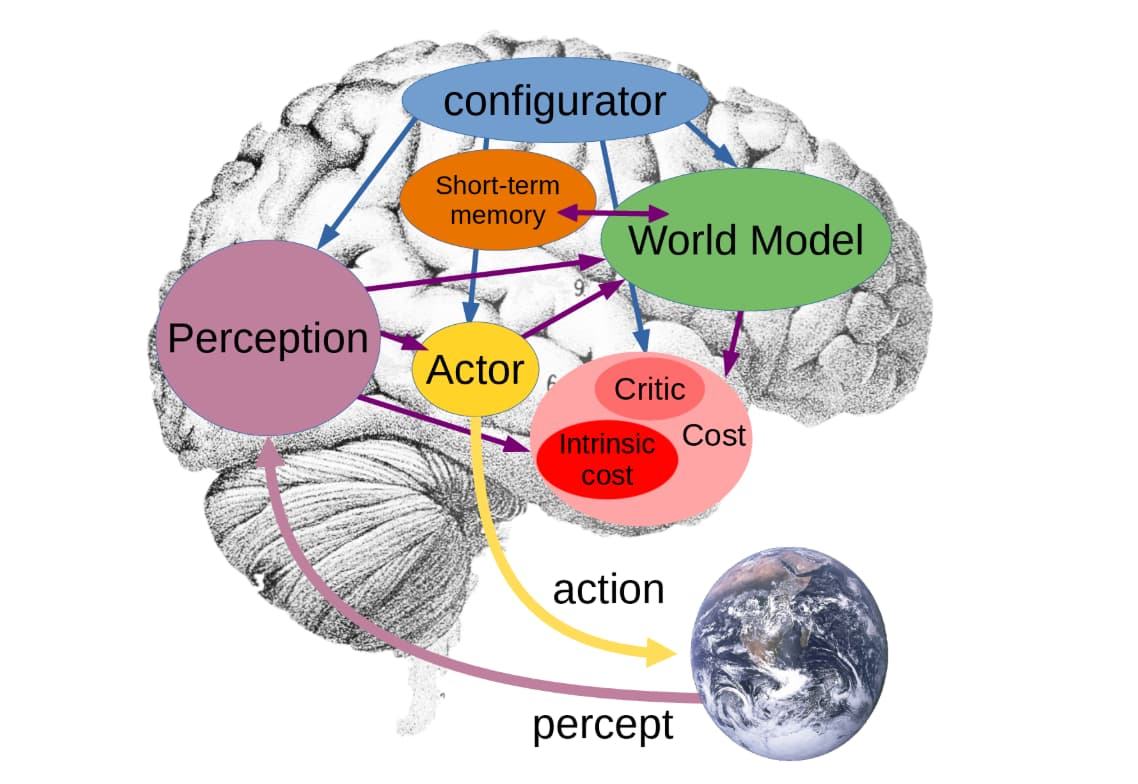
Abbildung: Systemarchitektur für autonome Intelligenz. Quelle: Yann LeCunn: A Path Towards Autonomous Machine Intelligence, Courant Institute of Mathematical Sciences, New York University
Diese Agenten arbeiten mit hierarchischen, vorhersagenden Architekturen. Ein flexibel einstellbares Kern-Weltmodell, das informationstechnisch an den präfrontalen Kortex von Säugetieren erinnert, erlaubt es der Maschine, Analogien zwischen ganz verschiedenen physischen Aufgaben zu ziehen und echtes Alltagswissen aus eigener Erfahrung abzuleiten. Begreift ein Roboter durch Anfassen, dass eine dünne Teetasse zerbrechlich ist, überträgt er dieses Wissen ohne weiteres Training auf ein Weinglas, ein rohes Ei oder eine Glühbirne. Er muss dafür keine Millionen neuer Texte über die Eigenschaften von Glas lesen.
In Europa gilt diese Entwicklung als wichtig für die technologische Souveränität. Renommierte Einrichtungen wie das Deutsche Forschungszentrum für Künstliche Intelligenz (DFKI) und staatliche Förderprogramme für physikalische KI betonen, dass Weltmodelle eine zentrale Voraussetzung für menschenähnliches Schlussfolgern sind. Fachleute erwarten, dass das Zusammenspiel von Sprachmodellen und physischen Robotiksystemen (Physical AI), eingebettet in eigene europäische Infrastrukturen, bis 2030 ein Marktpotenzial im hohen dreistelligen Milliardenbereich eröffnet.
Die Zukunft der KI liegt damit vor allem in Systemen der Embodied AI, die die Ursache-Wirkungs-Logik unserer Welt von Grund auf verstehen, in aufwendigen Simulationen die Zukunft durchrechnen und als eigenständige Akteure sicher in der echten Welt handeln. Reine Chatbots werden dabei zur Nebensache.
10. Häufig gestellte Fragen (FAQs)
Warum lernen LLMs physikalische Zusammenhänge nicht einfach, indem sie wissenschaftliche Texte und Physikbücher lesen?
Sprache ist stark verdichtet. Sie setzt enorm viel ungeschriebenes, sinnlich erfahrenes Grundwissen voraus. Kaum jemand schreibt auf, dass Wasser aus einem umgedrehten Glas nach unten läuft und den Boden nass macht, weil das für alle selbstverständlich ist. Ein LLM erfasst nur die statistische Verteilung der Wörter, ohne das Räumliche und Zeitliche je erlebt zu haben. Ihm fehlt die Verankerung in der Physik, und deshalb scheitert es an Aufgaben, die einem Kleinkind leicht fallen.
Was bedeutet „Closed-Loop State Tracking“ bei Weltmodellen, und warum ist es für autonome Systeme so wichtig?
In einer offenen Schleife, wie sie LLMs nutzen, reiht ein System seine Vorhersagen blind aneinander. Macht es einen Fehler, pflanzt dieser sich fort und wächst zur Halluzination. In einer geschlossenen Schleife berechnet ein Weltmodell laufend einen inneren Zustand der Umgebung. Nach jeder Aktion oder Vorhersage prüft es im nächsten Moment über seine Sensoren, ob die Realität zur Vorhersage passt. Stimmt etwas nicht, korrigiert es seinen Zustand sofort. Das verhindert, dass sich Fehlentscheidungen aufschaukeln, etwa ein übersehenes Hindernis im Verkehr, und macht das System verlässlich.
Warum verzichten besonders effiziente Ansätze wie Metas V-JEPA darauf, sichtbare Pixel zu erzeugen?
Jeden Pixel eines Videos exakt vorherzusagen, kostet enorm viel Rechenleistung, oft für Belanglosigkeiten wie das Rauschen einer Kamera oder die genaue Kräuselung von Wasser. V-JEPA arbeitet stattdessen in einem abstrakten latenten Raum. Es sagt nur die übergeordneten Eigenschaften einer Szene voraus, etwa „ein schweres Objekt fällt auf ein zerbrechliches und zerstört es“. Das spart beim Training viel Aufwand und führt zu einem robusteren physikalischen Verständnis, ohne dass optische Details ablenken.
Was ist der „Sim-to-Real Gap“ bei synthetischen Datensätzen, und wie betrifft er Weltmodelle?
Um physische KI sicher und günstig zu trainieren, nutzen Firmen große, computererzeugte Videodatensätze wie NVIDIAs SDG-Warehouse oder DriveSim und simulieren darin extreme Fälle, etwa schwere Unfälle oder brennende Lagerhallen. Weil diese Daten künstlich in Physik-Engines wie Omniverse entstehen, bleiben kleine Abweichungen zur Realität, gerade bei komplexer Reibung, weichen Materialien oder unberechenbarem menschlichem Verhalten. Diesen feinen Unterschied bezeichnet die Fachwelt als Sim-to-Real Gap. Modelle, die nur synthetisch gelernt haben, müssen deshalb vor dem Einsatz in sicherheitskritischen Bereichen in der echten Welt geprüft und mit echten Daten nachjustiert werden.
Wie unterscheiden sich die Hardware-Anforderungen von LLMs und Weltmodellen?
LLMs brauchen vor allem GPU-Cluster mit sehr viel Speicher (VRAM) und hoher Speicherbandbreite, um große Textkontexte zu verarbeiten. Weltmodelle verlangen eine deutlich aufwendigere, gemischte Infrastruktur. Weil sie auf hochdimensionalen Video- und Sensordaten lernen und physikalische Simulationen in Echtzeit rechnen, brauchen sie zusätzlich Raytracing-Ressourcen, riesige Speichersysteme, die oft im Petabyte-Bereich liegen und sehr schnelle Netze zwischen den Servern. Das treibt Komplexität und Wartungskosten in den Rechenzentren spürbar nach oben.
Ihr Wartungsspezialist für alle großen Hardware Hersteller
Durch Jahrzehnte lange Erfahrung wissen wir worauf es bei der Wartung Ihrer Data Center Hardware ankommt. Profitieren Sie nicht nur von unserer Erfahrung, sondern auch von unseren ausgezeichneten Preisen. Holen Sie sich ein unverbindliches Angebot und vergleichen Sie selbst.
Weitere Artikel

US-Regierung legt bei Anthropic den Kill-Switch um + Google haftet für KI-Lügen + SpaceX wird zum Billionen-IPO
Shownotes Die große These Über künstliche Intelligenz entscheiden diese Woche nicht mehr die Entwickler, sondern Gerichte, Regierungen und
Claude Fable 5: Das beste KI-Modell der Welt – nur gefiltert
Shownotes Die große These Die beste Intelligenz der Welt wird ab jetzt rationiert: Anthropic verkauft mit Claude Fable

Server-Ersatzteile – Verfügbarkeit 2026: Diese Modelle sollten IT-Verantwortliche jetzt prüfen
Unser Praxisleitfaden für IT-Verantwortliche und Entscheider: welche Server-Generationen 2026 ins Risiko laufen, welche Teile zuerst knapp werden und wie Sie
