


World Models können die IT-Wartung, wie wir sie kennen, komplett verändern und menschliche Eingriffe überflüssig machen.
Aktuelle KI-Rechenzentren haben mit Anlagen von früher wenig gemein. Wo bisher nur Web-Hosting und Datenbanken betrieben wurden, stehen heute Hochleistungs-GPU-Cluster, die pro Rack 50 bis über 100 Kilowatt Abwärme erzeugen. So viel Abwärme bewältigt eine klassische Luftkühlung nicht mehr. Die Branche muss deshalb auf Flüssigkeitskühlung umsteigen.
Damit wächst die Zahl der Bauteile, die ausfallen können: Pumpen, Wärmetauscher, Verteiler, Tausende Steckverbindungen. Ein unbemerkter Druckabfall in einem Verteiler kann binnen Sekunden Dutzende GPUs im Wert von mehreren Hunderttausend Euro zerstören.
Ein fester Wartungsplan alle sechs Monate passt nicht zu KI-Lasten, die thermisch sprunghaft verlaufen. Gefragt ist eine Diagnose, die in Echtzeit läuft und die Strömungsphysik versteht.
Eine weitere Herausforderung kommt hinzu: der Fachkräftemangel. Er betrifft insbesondere die IT-Branche. Die Verfügbarkeit von qualifiziertem Personal engt die Standortauswahl von Rechenzentren ein.
Ein Ausweg aus diesen Problemen kann der Einsatz von World Models in der Wartung sein: Damit können Ausfälle frühzeitig vorhergesehen werden, und die Behebung technischer Defekte lässt sich ohne Personal oder remote durchführen.
Was ein World Model von einem Sprachmodell unterscheidet
Sprachmodelle (LLMs) wie GPT, Claude oder Gemini sagen das jeweils nächste Wort voraus. Für die Textarbeit sind sie stark: Logfiles auswerten, Dokumentation zusammenfassen, Code schreiben. Von der physischen Welt haben sie aber kein Bild. Schwerkraft, Reibung oder Wärmeströmung kennen sie nicht. Ein Sprachmodell gleicht seine Ausgaben nie mit der Wirklichkeit ab und kann sich so in Fehlern verrennen.
Ein World Model lernt dagegen aus Sensordaten: Video, Audio, Lidar sowie Bewegungs- und Kraftdaten. Daraus baut es ein inneres Modell der physikalischen Welt und sagt voraus, wie sich ein System im nächsten Moment verhalten wird. Weicht die Realität von dieser Vorhersage ab, korrigiert es sich sofort.
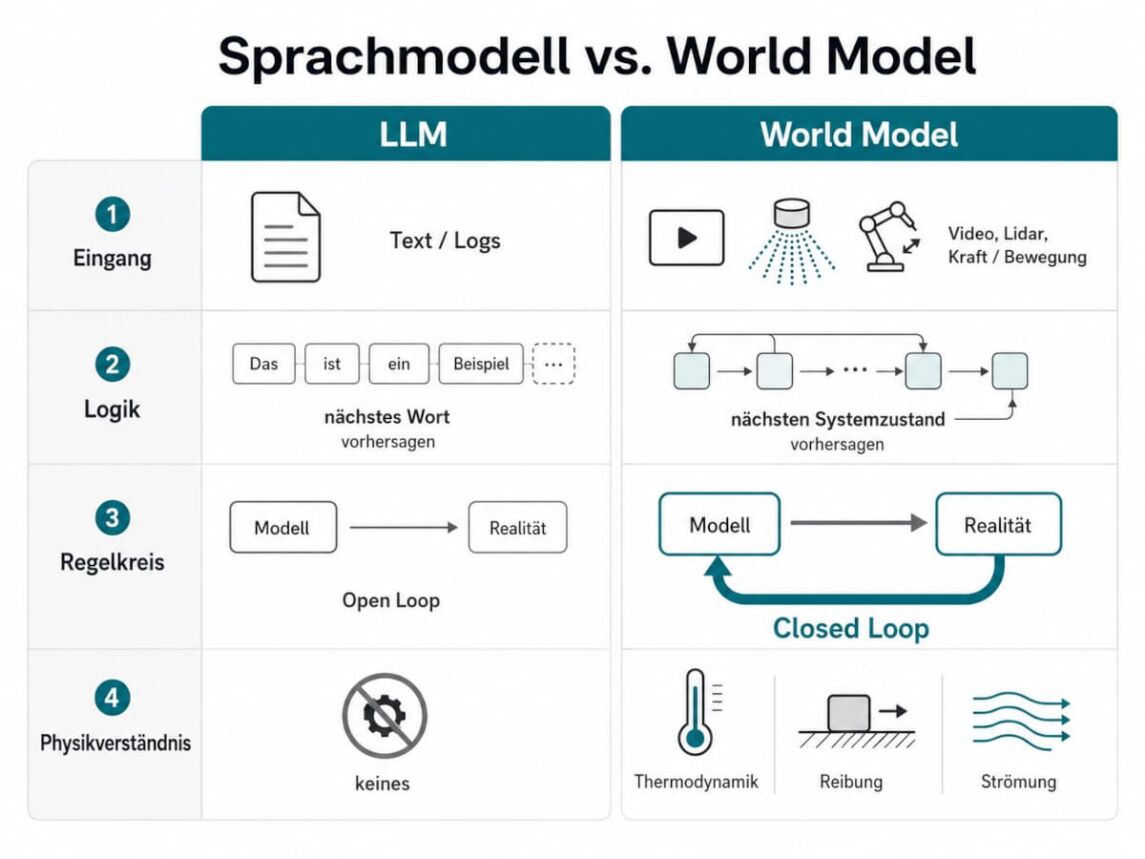
Abbildung: Sprachmodell vs. World Model
Warum klassische Wartung an ihre Grenzen stößt
Jede Pumpe, jeder Mikrokanal und jeder Steckverbinder in einem flüssigkeitsgekühlten Rechenzentrum bringt Fehlerquellen mit, die luftgekühlte Räume nie hatten: galvanische Korrosion in den Kanälen, Kavitation in den Pumpen, Materialien, die sich nicht vertragen. Selbst übliche Predictive-Maintenance-Systeme, die nur Anomalien in einzelnen Sensorwerten suchen, übersehen die Zusammenhänge zwischen Strömung, Druck und Temperatur oft zu spät.
Läuft Ihre Wartung noch nach Kalender?
Lassen Sie Ihre Wartungsstrategie für Server, Storage und Netzwerk von hardwarewartung.com prüfen.
Wie World Models Ausfälle vorhersagen
Einen Ausfall zu verhindern, heißt, ihn vorauszuberechnen. Klassisch erledigt das zum Beispiel die thermische Strömungssimulation (CFD), wie sie etwa Meta für seine Rechenzentren einsetzt. Der Haken: Für ein großes Rechenzentrum rechnet eine solche Simulation Stunden bis Tage. Bei einem plötzlichen Druckabfall, bei dem in Millisekunden klar sein muss, welches Ventil schließt und welche Last gedrosselt wird, ist das zu langsam.
Hier setzt Physics-Informed Machine Learning (PIML) an. Ein neuronales Netz lernt die Vorhersage und bekommt die physikalischen Gesetze fest eingebaut. Trifft es eine Vorhersage, die Energie- oder Massenerhaltung verletzt, bestraft das Training es dafür. So braucht das Modell viel weniger Trainingsdaten, und es bleibt auch bei unbekannten Störfällen physikalisch plausibel.
In einer Fallstudie mit einem Produktionsrechenzentrum sagten solche Modelle auf Basis von NVIDIA PhysicsNeMo die Temperaturverteilung in Echtzeit voraus, mit einem mittleren Fehler von nur 0,18 °C. Eine Vorhersage im Millisekundenbereich ersetzt damit die stundenlange CFD-Rechnung.

Abbildung: Nvidia PhysicsNeMo
Ein solches Modell arbeitet in drei Stufen:
- Es sagt Zustände wie etwa einen drohenden thermischen Runaway oder den Ladezustand der USV-Batterien voraus.
- Es greift steuernd ein, zum Beispiel über eine Kühlungsregelung, die das thermische Limit der Server nie überschreitet.
- Und es passt sich an, sobald neue Server eingebaut oder Racks umgestellt werden.

Abbildung: Die drei Stufen eines World Models im Rechenzentrum
Vom digitalen Zwilling zum lebenden Zwilling
Ein einzelnes Vorhersagemodell genügt nicht, um die IT-Wartung im Rechenzentrum per KI zu betreiben. Es braucht eine Architektur, die Trainingsdaten erzeugt, Modelle trainiert und sie im Betrieb laufen lässt. In der Forschung läuft das unter dem Begriff Physical AI. Drei Bausteine gehören dazu:
- physikalische Simulatoren wie OpenFOAM, die synthetische Trainingsdaten liefern
- eine Plattform für Training und Betrieb der Modelle wie NVIDIA PhysicsNeMo und
- ein digitaler Zwilling, der das Rechenzentrum als exaktes 3D-Abbild führt, etwa NVIDIA Omniverse.
Anders als ein klassisches Gebäudemodell entwickelt sich der digitale Zwilling weiter. Er lernt laufend aus Sensordaten mit und dient als Grundlage für jede Wartungsentscheidung. Man spricht dabei auch vom „lebenden“ digitalen Zwilling.
Roboter, die selbst Hand anlegen
Eine gute Vorhersage nützt wenig, wenn die Reparatur zu lange dauert. Fachkräfte, welche die vom Modell gelieferten Handlungsempfehlungen umsetzen, sind schwer zu finden. Die nächste Stufe sind deshalb Roboter mit einem World Model an Bord. Man spricht hier auch von On-Edge-AI.
Klassische Wartungsroboter folgen festen Karten oder Magnetstreifen am Boden. Steht ein Kabel im Weg, bleiben sie stehen und warten auf einen Menschen, der ihnen hilft. Ein Roboter mit World Model reagiert dynamisch: Registriert er eine kleine Kühlmittel-Leckage, simuliert er die rutschige Stelle, rechnet sich aus, dass er dort die Kontrolle verlieren könnte, und wählt selbst eine andere Route durch den Nachbargang.
Die Königsdisziplin ist die zweihändige Arbeit in einem Gewirr aus Kabeln. Microsoft Research entwickelt Roboter, die optische Transceiver einsetzen, Glasfasern reinigen und Netzwerkkabel verlegen. Kabel sind schwer berechenbar, weil sie sich biegen und verhaken können. Die Roboter setzen auf ein 3D-Szenenverständnis, schieben störende Kabel mit dosierter Kraft beiseite und bringen den Greifer exakt in Position.
Lange war offen, wie ein Roboter merkt, dass er gerade einen Fehler macht. Forscher aus Stanford trainieren dafür ein World Model im latenten Raum eines vortrainierten Bildmodells, des NVIDIA Cosmos Tokenizer. Das Modell sagt fortlaufend den nächsten physikalischen Zustand voraus und gibt zugleich an, wie sicher es sich ist. Verkantet ein Stecker oder rutscht der Greifer ab, weicht die Realität von der Vorhersage ab. Der Unsicherheitswert springt hoch, der Roboter bricht ab, bevor Hardware Schaden nimmt, und schlägt damit klassische statistische Anomalieerkennung deutlich.
Startups wie Boost Robotics bauen schon Roboter, die Rechenzentren laufend überwachen und es einem einzelnen Experten erlauben, Hardware an vielen Standorten aus der Ferne zu diagnostizieren und zu reparieren. Microsoft fasst diese Entwicklung unter dem Stichwort „self-maintaining data center“ zusammen.
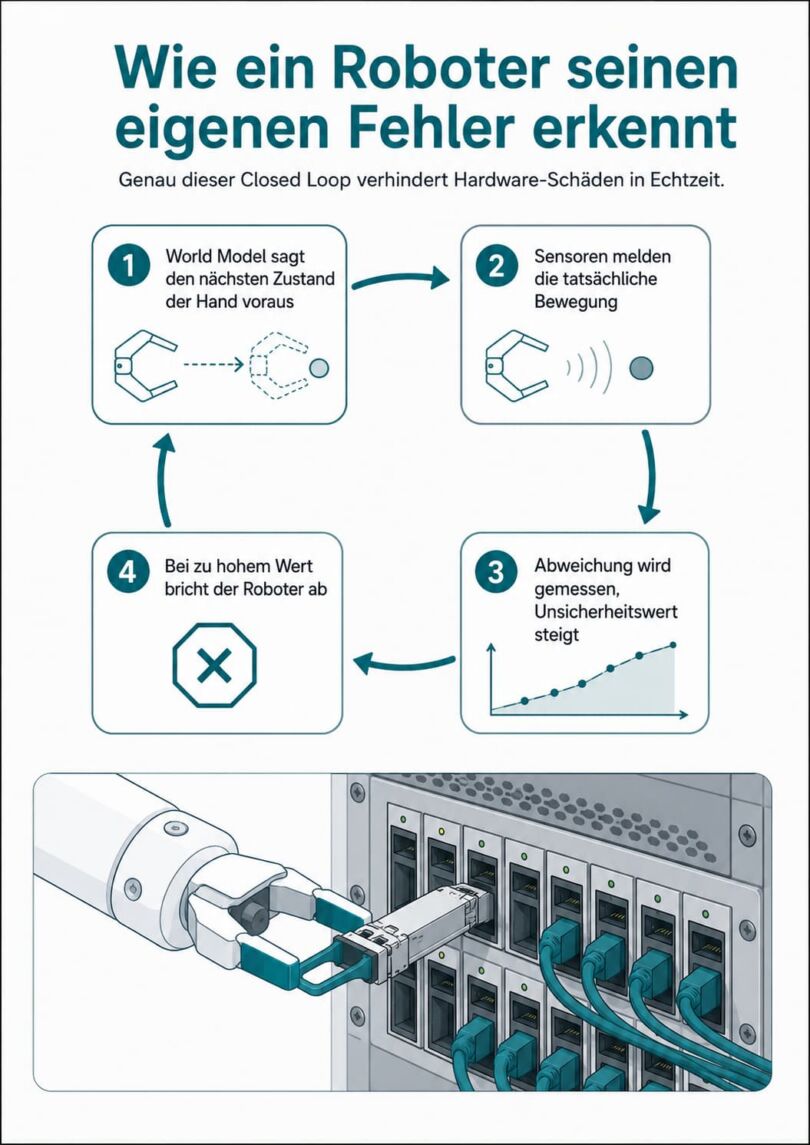
Abbildung: Wie ein Roboter seinen eigenen Fehler erkennt
Hardwarewartung vom Spezialisten
Hardwarewartung.com betreut Ihre Systeme vor Ort und aus der Ferne, herstellerübergreifend.
Was das für Standorte, Kosten und Nachhaltigkeit heißt
Wenn ein Rechenzentrum sich selbst wartet, kann sich das auf die Standortwahl auswirken. Bisher standen große Anlagen nah an Ballungsräumen, auch weil dort genug Fachkräfte für schnelle Einsätze wohnen. Der Strombedarf der KI-Hardware treibt neue Rechenzentren aber an abgelegene Orte: neben Wasserkraftwerke, an Standorte mit Geothermie oder großen Solarparks. Dort gibt es kaum lokales IT-Fachpersonal.
Das „self-maintaining data center“ kann hier Abhilfe schaffen: Tritt ein Fehler auf, kann sich ein Experte auf einem anderen Kontinent einschalten und über einen Roboter ins System eingreifen, um das Problem zu beheben, oder er lässt den Roboter den vorgeschlagenen Handgriff selbst ausführen. Das senkt Ausfallzeiten und Betriebskosten spürbar und hilft, vereinbarte SLAs zu halten.
Eine vorausschauende Wartung tauscht Bauteile nur dann, wenn ihr Zustand es verlangt, statt zu früh oder erst nach einem Schaden. Das spart Kosten für Hardware und schont die Ressourcen. Und weil das Modell die Kühlung genau auf die aktuelle Last abstimmt, statt das ganze Rechenzentrum auf Maximum herunterzukühlen, sinkt der Stromverbrauch und der PUE-Wert verbessert sich.
Forscher von EURECOM und Ericsson sehen darin den Anfang eines „Internet of Physical AI Agents“: einer Infrastruktur, in der handelnde Maschinen vernetzt sind, so wie das Internet einst Computer verbunden hat.
Was Verantwortliche jetzt tun sollten
Einfache IoT-Sensoren mit Schwellenwert-Logik reichen für die automatisierte Wartung moderner KI-Hardware nicht mehr aus. Wer neue Wartungssoftware prüft, sollte fragen, ob ein physikbasiertes World Model dahintersteht oder nur Grenzwerte überwacht werden.
Der Umstieg ist einigermaßen komplex. Standardisierte Schnittstellen, modulare Racks und klare Regeln, was die KI autonom darf und was ein Mensch entscheidet, sind die Voraussetzung.
World Models werden zum Werkzeug, mit dem die teuerste digitale Infrastruktur unserer Wirtschaft am Laufen gehalten werden kann, auch dort, wo kein Techniker in der Nähe ist.
Sie planen oder betreiben Hardware in einem anspruchsvollen Umfeld?
Häufige Fragen
Was ist ein World Model in einfachen Worten?
Ein KI-Modell, das aus Sensordaten ein inneres Bild der physikalischen Welt aufbaut und vorhersagt, wie sich ein System als Nächstes verhält. Für den Wartungsbetrieb im Rechenzentrum heißt das: Es rechnet Temperatur, Druck und Strömung voraus und erkennt eine Störung, bevor sie eintritt.
Warum reicht klassische Predictive Maintenance nicht mehr?
Übliche Systeme prüfen bestimmte Sensorwerte auf Anomalien. In flüssigkeitsgekühlten Racks hängen Druck, Strömung und Temperatur aber eng zusammen. Ein World Model kennt diese physikalischen Zusammenhänge und sieht mögliche Kaskadeneffekte vorher, etwa einen thermischen Runaway nach einem Pumpenausfall.
Ab wann lohnt sich der Umstieg?
Sobald Racks mit hoher Leistungsdichte und Flüssigkeitskühlung im Spiel sind, steigt das Ausfallrisiko stark. Dann zahlt sich eine vorausschauende, physikbasierte Diagnose schnell aus: Ein einziger verhinderter Thermal Runaway rettet Hardware im Wert von mehreren Hunderttausend Euro.
Ersetzen Roboter das Wartungspersonal?
Kurzfristig nicht. Roboter übernehmen gefährliche und wiederkehrende Handgriffe und erlauben es Fachleuten, aus der Ferne zu arbeiten. Komplexe Entscheidungen und die Aufsicht bleiben beim Menschen. Realistisch ist ein Modell, bei dem ein Experte mehrere Standorte zugleich betreut.
Ihr Wartungsspezialist für alle großen Hardware Hersteller
Durch Jahrzehnte lange Erfahrung wissen wir worauf es bei der Wartung Ihrer Data Center Hardware ankommt. Profitieren Sie nicht nur von unserer Erfahrung, sondern auch von unseren ausgezeichneten Preisen. Holen Sie sich ein unverbindliches Angebot und vergleichen Sie selbst.
Weitere Artikel

Server-Ersatzteile – Verfügbarkeit 2026: Diese Modelle sollten IT-Verantwortliche jetzt prüfen
Unser Praxisleitfaden für IT-Verantwortliche und Entscheider: welche Server-Generationen 2026 ins Risiko laufen, welche Teile zuerst knapp werden und wie Sie

LLMs vs. World Models: Welcher Ansatz eignet sich für welches Problem?
Große Sprachmodelle (LLMs) scheitern dann, wenn zum Lösen einer Aufgabe echte physikalische Erfahrungen nötig sind. Dann kommen World Models

Claude Opus 4.8, Anthropic-IPO und die Iran-Öl-Falle für die KI-Blase
Shownotes Die große These KI ist keine reine Software-Story mehr - sie ist Infrastruktur, Energiepolitik, Kapitalmarktstory und Cybersecurity-Risiko
