


Die Abhängigkeit von KI aus den USA ist für viele Unternehmen ein großes Risiko. Wir zeigen, wie Unternehmen diese Abhängigkeit reduzieren und komplett vermeiden.
Claude Fable dürfte vielen Unternehmen in Deutschland und Europa eine Warnung sein: Wenige Tage, nachdem Anthropic sein bisher leistungsfähigstes Modell auf den Markt gebracht hatte, musste es den Zugang auf Druck der US-Regierung schon wieder abschalten (hören Sie dazu auch unsere Podcast-Folge vom 18. Juni). Diejenigen, die das Modell bereits fest in ihre produktiven Abläufe integriert hatten, mussten reagieren und umstellen.
Hinzu kommt die Unsicherheit über die Verwendung sensibler Daten, was zwei konkrete Beispiele demonstrieren: Ein Entwickler bei Samsung fügt den internen Quellcode in einen US-Chatbot ein, um schneller einen Fehler zu beheben. Kurz darauf steht die Frage im Raum: Wo liegt dieser Code jetzt, und wer konnte ihn mitlesen? Bei der australischen NSW Reconstruction Authority lief es ähnlich, dort flossen Gesundheitsdaten tausender Menschen über ein öffentliches KI-Tool ab.
All das trifft den Nerv, der viele Geschäftsführer und IT-Leitungen gerade umtreibt: Die Werkzeuge erleichtern die Arbeit spürbar, doch die Kontrolle über die eigenen Daten rutscht weg, wie auch die Allianz für Cybersicherheit des Bundesamts für Sicherheit in der Informationstechnik bestätigt.
Manche Unternehmen arbeiten längst mit großen US-Modellen und merken, dass sie sich in ein einziges Ökosystem hineinmanövriert haben, aus dem ein Wechsel teuer und aufwändig wäre. Andere stehen erst am Anfang und wollen die Weichen gleich so stellen, dass solche Abhängigkeiten gar nicht erst entstehen. Für beide gilt dieselbe gute Nachricht: Eine eigenständige, rechtssichere KI-Strategie ist heute machbar. Europa hat bei Modellen, Cloud-Infrastruktur und Werkzeugen aufgeholt, und der Werkzeugkasten dafür liegt bereit.
Das Wichtigste in Kürze
- Europäische KI-Modelle sind konkurrenzfähig. Mistral, Aleph Alpha, Teuken-7B (OpenGPT-X) oder das Industriemodell Soofi S decken viele Aufgaben ab und sind bei deutscher Sprache, Transparenz und Datenschutz oft im Vorteil.
- Souveräne Clouds in Europa existieren. STACKIT, die Open Sovereign Cloud der Telekom sowie OVHcloud und Scaleway bieten Rechenleistung in Europa, teils mit Verschlüsselung sogar während der Verarbeitung.
- Abhängigkeit steckt in Verträgen, Schnittstellen, im Wissen der eigenen Teams und in fehlenden Ausstiegsplänen.
- Der US CLOUD Act greift auch in Europa. US-Behörden können auf Daten zugreifen, selbst wenn diese in einem europäischen Rechenzentrum liegen, sofern der Anbieter US-amerikanisch ist.
- Ein KI-Gateway entkoppelt. Es schaltet sich zwischen Anwender und Modell, filtert sensible Daten heraus, protokolliert alles und erlaubt es, das Modell im Hintergrund auszutauschen, ohne dass die Belegschaft etwas merkt.
- Der Einstieg gelingt schrittweise. Erst Bestand und Risiken aufnehmen, dann die Architektur standardisieren, dann das Gateway aufsetzen, dann Wissen breit aufbauen und den Ausstieg üben.
- Förderung senkt die Hürde. Bund und EU stellen Geld und Beratungsstrukturen bereit, gerade für kleine und mittlere Unternehmen.
Was „digitale Souveränität“ wirklich meint
“Digitale Souveränität” klingt nach Abschottung, gemeint ist aber das Gegenteil von Hilflosigkeit. Das Kompetenzzentrum Öffentliche IT und das BSI beschreiben digitale Souveränität als die Fähigkeit, in der digitalen Welt selbstbestimmt und sicher zu handeln. Der Branchenverband Bitkom überträgt das auf die Wirtschaft: Ein Unternehmen soll handlungsfähig bleiben, auch wenn ein Anbieter die Preise anzieht, einen Dienst abkündigt oder politische Verwerfungen den Zugang erschweren.
Souveränität heißt also nicht, grundsätzlich jeden US-Dienst zu verbannen. Sie heißt, jederzeit wechseln zu können, ohne dass der Betrieb zusammenbricht. Ganz auf moderne KI zu verzichten, wäre dabei der falsche Schluss. Wer abwartet, verliert den Anschluss beim Tempo und bei der Qualität. Der Weg führt über bewusste Architektur.
Der US CLOUD Act erlaubt US-Behörden den Zugriff auf Unternehmensdaten, auch wenn diese physisch in Frankfurt oder Paris liegen. Dazu kommen Exportkontrollen und abrupte Kurswechsel großer Anbieter. Und die eingangs genannten Datenabflüsse bei Samsung und der NSW Reconstruction Authority zeigen, wie schnell sensible Inhalte in fremde Trainingsdaten geraten, wenn Mitarbeitende öffentliche Tools verwenden.
Wo die Abhängigkeit wirklich sitzt
Viele Verantwortliche denken bei Abhängigkeit zuerst an den Serverstandort. Der ist wichtig, aber nur ein Teil des Bildes. Bitkom unterscheidet fünf Felder, in denen sich Unternehmen festfahren:
- Auf der organisatorischen Ebene fehlt oft eine klare Linie. Fachabteilungen kaufen KI-Dienste auf eigene Faust ein, es entsteht eine Schatten-IT ohne Überblick und ohne Plan B.
- Technisch verzahnen sich Kernprozesse mit geschlossenen Schnittstellen und proprietären Datenformaten. Je tiefer diese Verzahnung, desto teurer und langwieriger wird später jeder Wechsel.
- Hinzu kommt eine Kompetenz-Falle: Wenn Teams jahrelang nur die Werkzeuge eines einzigen Anbieters lernen, verlernen sie, Alternativen überhaupt zu bewerten. Diese Bindung blockiert Veränderung von innen.
- Wirtschaftlich fehlt ohne getestete Ausstiegsoption jede Verhandlungsmacht, das Unternehmen muss Preiserhöhungen schlucken.
- Und rechtlich kann ein Gerichtsurteil oder eine Sanktion einen Dienst über Nacht unbrauchbar machen.
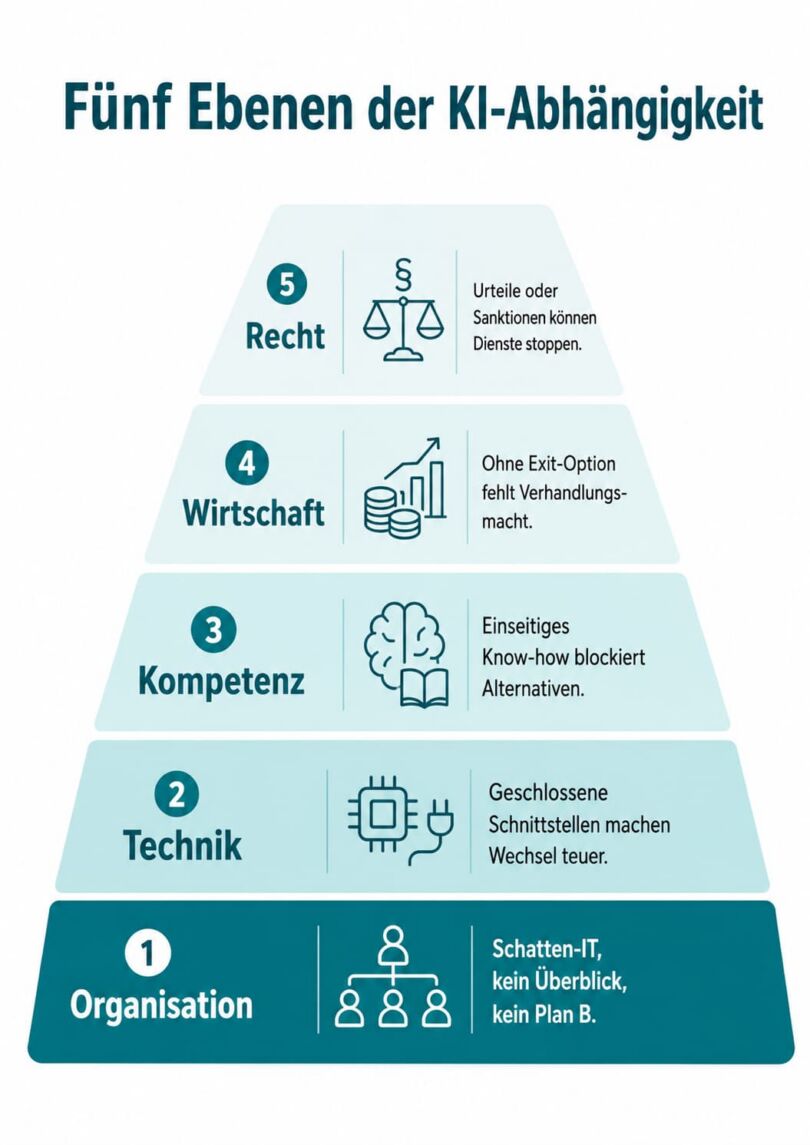
Abbildung: Die 5 Ebenen der KI-Abhängigkeit
Europäische Modelle, die im Alltag funktionieren
Der KI-Markt gehört nicht mehr allein den US-Konzernen. Die EU hat über das EuroHPC-Programm rund zehn Milliarden Euro bis 2027 für Rechenzentren und „KI-Fabriken“ zugesagt, und das Ergebnis sieht man an konkreten Modellen.
Das französische Mistral AI zählt zu den sichtbarsten Anbietern. Mistral baut für rund 1,2 Milliarden Euro ein eigenes Rechenzentrum in Schweden und fährt zweigleisig: Offene Modelle wie Mixtral oder das auf Programmierung spezialisierte Codestral lassen sich herunterladen und vollständig auf eigener Hardware betreiben. Dazu kommen kommerzielle Modelle wie Mistral Large. Wer ein offenes Modell selbst hostet, schickt keine sensiblen Daten mehr über den Atlantik.
Aleph Alpha aus Heidelberg setzt einen anderen Schwerpunkt. Mit der Plattform PhariaAI zielt das Unternehmen auf Behörden, kritische Infrastrukturen und stark regulierte Branchen wie Banken oder Kliniken. Prüfer können mathematisch nachvollziehen, welche Eingabe oder welches Dokument zu einer bestimmten Antwort geführt hat. Für Audits ist das Gold wert.
Aus der geförderten Forschung stammt Teuken-7B aus dem Projekt OpenGPT-X, geführt von den Fraunhofer-Instituten IAIS und IIS und trainiert auf dem Jülicher Supercomputer JUWELS. Das Modell wurde für alle 24 Amtssprachen der EU gebaut und stützt sich zu fast der Hälfte auf nicht-englische Trainingsdaten.
Das Training des Modells auf nicht-englischen Sprachen wie Deutsch bringt viele Vorteile: Deutsch bildet lange Komposita, und US-Modelle zerlegen solche Wörter in viele kleine Bruchstücke, was jede Anfrage teurer macht. Der Tokenizer von Teuken-7B fasst diese Strukturen kompakter, so dass deutsche Texte im Betrieb günstiger sind. Das Modell steht unter der freien Apache-2.0-Lizenz und ist an das europäische Gaia-X-Ökosystem angebunden.
Für die Industrie gibt es seit Kurzem Soofi S, entstanden im vom KI Bundesverband koordinierten Soofi-Konsortium unter Beteiligung von Fraunhofer und DFKI. Das Modell hat 30 Milliarden Parameter, kombiniert in seiner Architektur Transformer- mit Mamba-Komponenten und wurde mit 27 Billionen Tokens auf hohen Datendurchsatz bei sparsamem Stromverbrauch ausgelegt. Es läuft auf europäischer Infrastruktur wie der Industrial AI Cloud der Deutschen Telekom. Das Konsortium veröffentlicht neben den Modellgewichten auch die komplette Dokumentation der Trainingsmethodik, sodass Unternehmen ihre KI lückenlos prüfen können.
Bei Spezialaufgaben führt Europa ohnehin. DeepL aus Köln übersetzt auf höchstem Niveau und speichert die Texte von Geschäftskunden standardmäßig nicht; das Kölner Prinzip heißt “Datenschutz ab Werk”.
Bei der Bildgenerierung hat das deutsche Black Forest Labs mit seinen FLUX-Modellen eine viel beachtete Alternative geschaffen, und für das Zusammenspiel mehrerer Modelle bietet die deutsche Plattform Langdock einen datenschutzkonformen Zugang, ohne dass Firmendaten ins Training fremder Modelle sickern.
Souveräne Cloud und der neue BSI-Standard
Ein europäisches Modell verliert seinen Sinn, wenn es auf der Plattform eines US-Anbieters läuft, der dem CLOUD Act unterliegt. Die Wahl der Infrastruktur entscheidet also mit.
Damit aus „Cloud-Souveränität“ mehr wird als ein Schlagwort, hat das BSI 2026 den Kriterienkatalog C3A veröffentlicht („Criteria enabling Cloud Computing Autonomy“). Er übersetzt das europäische Cloud Sovereignty Framework in prüfbare Anforderungen und setzt den bestehenden BSI-C5-Sicherheitskatalog voraus.
C3A prüft sechs Bereiche der Souveränität::
- strategische
- rechtliche
- datenbezogene
- betriebsbezogene
- lieferkettenbezogene und
- technologiebezogene.
Rechtlich verpflichtend ist der Katalog nicht, doch im öffentlichen Einkauf und bei kritischen Infrastrukturen wird er schnell zum harten Auswahlkriterium. Für Unternehmen heißt das: Wer C3A im Beschaffungsprozess als Mindestanforderung verankert, sichert sich Datenkontrolle und Ausstiegsfähigkeit vertraglich ab.
Der Markt liefert die passenden Anbieter. STACKIT, die Cloud-Marke der Schwarz-Gruppe, setzt auf Open-Source-Technik und bietet Confidential Computing: Sensible Daten bleiben sogar während der Verarbeitung im Arbeitsspeicher verschlüsselt, sodass weder Dritte noch die Administratoren des Betreibers hineinschauen können.
Die Open Sovereign Cloud der Telekom (T-Systems) baut ebenfalls auf offene Technik, ist an Gaia-X angebunden und erfüllt mit Hardware-Sicherheitsmodulen und Confidential Computing die strengen Vorgaben der gematik sowie den Schutz von Berufsgeheimnissen nach § 203 StGB, was sie für klinische und juristische Anwendungen brauchbar macht.
GPU-Leistung liefern zusätzlich die französischen Anbieter OVHcloud und Scaleway.
Nicht jedes Unternehmen braucht gleich mächtige Server in der Cloud. Kleine Sprachmodelle laufen problemlos auf eigener Hardware. Für einfache Zusammenfassungen oder Textentwürfe reicht oft eine lokale Grafikkarte Speicher. Werkzeuge wie LM Studio oder Ollama machen den lokalen Betrieb leicht, für Bilder eignen sich zum Beispiel Fooocus oder AUTOMATIC1111. Wer mit dem lokalen Ansatz startet, sammelt Erfahrung, bevor größere Investitionen anstehen.
Der Schlüssel zur Unabhängigkeit: das KI-Gateway
Sobald Hunderte Mitarbeiter gleichzeitig KI verwenden sollen, stößt lokale Hardware an ihre Grenzen. Hier kommt ein Bauteil ins Spiel, das den Unterschied zwischen Abhängigkeit und Kontrolle ausmacht: das KI-Gateway.
Ein Gateway sitzt als zentraler Kontrollpunkt zwischen den internen Anwendungen und den Modellen im Hintergrund. Die Belegschaft spricht nie direkt mit einem Modell; jede Anfrage läuft über diese Zwischenschicht. Das Gateway prüft Zugriffsrechte, maskiert oder blockiert personenbezogene Daten, bevor sie an ein Modell gehen, und protokolliert jeden Vorgang revisionssicher für die Nachweispflichten der DSGVO.
Der eigentliche Gewinn liegt im Austausch. Weil die Anwendungen nur mit dem Gateway reden, kann die IT das Modell dahinter jederzeit wechseln, von einem US-Modell zu Teuken-7B oder Mistral, ohne dass eine einzige Fachanwendung umgebaut werden muss. Genau diese Entkopplung macht aus einem Lock-in eine freie Wahl.
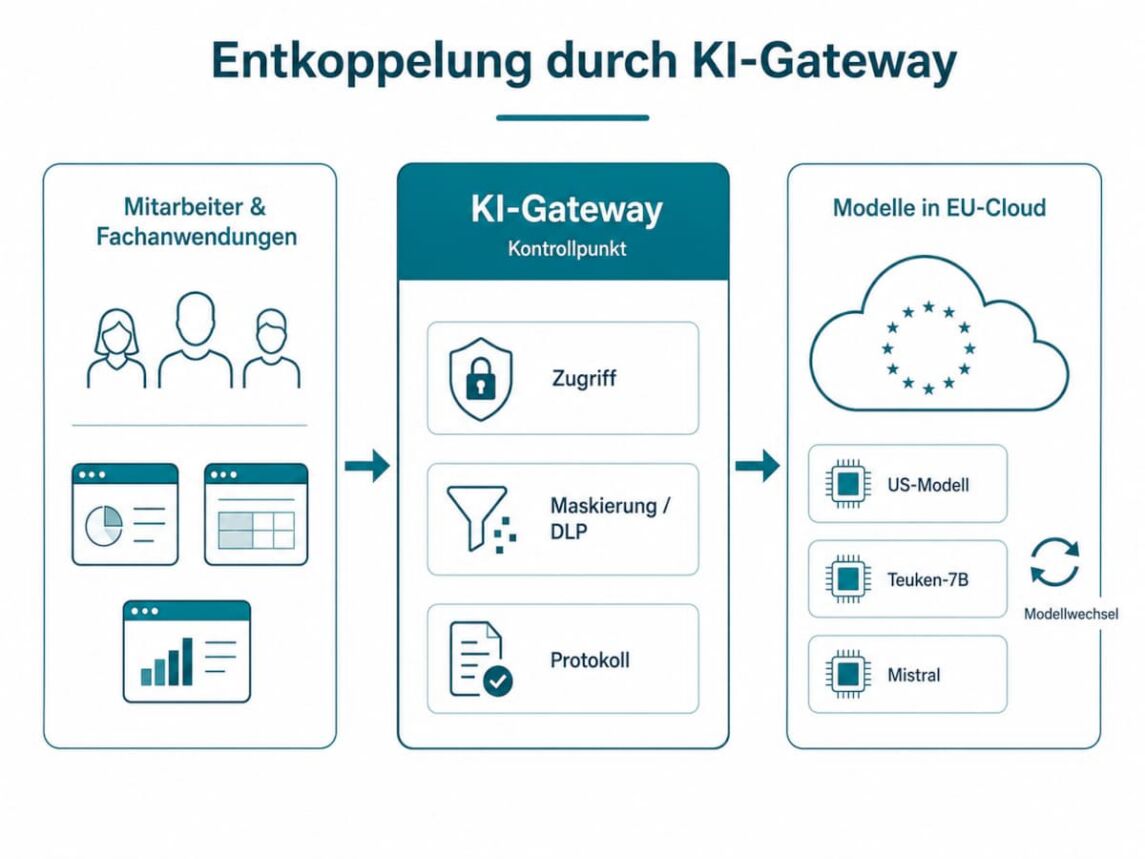
Abbildung: Entkoppelung durch KI-Gateway
DSGVO und EU AI Act
Wer KI in Europa einsetzt, bewegt sich in einem dichten Regelwerk. Zwei Vorschriften greifen ineinander. Der EU AI Act regelt die KI als Produkt, die DSGVO weiterhin den Umgang mit personenbezogenen Daten.
Beim Datenschutz bereiten große Sprachmodelle zwei besondere Probleme. Modelle können sich Trainingsinhalte einprägen und auf passende Eingaben hin wörtlich wiedergeben, darunter Namen, Adressen oder Gesundheitsdaten. Und sie halluzinieren, erfinden also plausibel klingende, aber falsche Aussagen, was bei echten Personen schnell deren Rechte verletzt.
Für jede Phase, vom Training über das Feintuning bis zur täglichen Abfrage, braucht es eine geprüfte Rechtsgrundlage. Beim Hosting in einer fremden Cloud ist ein Vertrag zur Auftragsverarbeitung Pflicht. Der Transfer in die USA verlangt zusätzlich aufwendige Folgenabschätzungen und Standardvertragsklauseln, ein Aufwand, der bei einer zertifizierten europäischen Cloud schlicht entfällt.
Der EU AI Act ordnet KI nach Risiko in vier Stufen, von verboten bis kaum reguliert. Wichtig für die Praxis: Über die Risikoklasse entscheidet der konkrete Einsatz; das Modell selbst dagegen nicht. Dasselbe Modell ist beim Zusammenfassen von Marketingtexten harmlos, im automatischen Bewerber-Screening fällt es sofort in die Hochrisikoklasse mit strengen Pflichten zu Aufsicht, Dokumentation und Protokollierung. Passt ein Unternehmen ein offenes Modell stark für eigene Hochrisikozwecke an, kann es rechtlich selbst zum Anbieter werden und trägt dann die vollen Pflichten.
Für große Allzweckmodelle gibt es Sonderregeln. Übersteigt die Rechenleistung beim Training einen Schwellenwert von rund 10²⁵ Rechenoperationen (FLOPs), gilt ein Modell als systemisches Risiko und unterliegt harten Auflagen.
Für den Mittelstand wichtiger ist die Open-Source-Ausnahme: Wer ein offenes Modell für interne, unkritische Zwecke wie Wissensmanagement verwendet, ist von vielen Dokumentationspflichten befreit. Die EU legt „Open Source“ allerdings streng aus, um Etikettenschwindel zu verhindern. Drei Bedingungen müssen zusammenkommen: freie Lizenz mit Recht auf Nutzung und Weitergabe, öffentlich zugängliche Gewichte und Architektur, und keinerlei Vermarktung des Modells selbst. Für Modelle mit systemischem Risiko greift die Ausnahme nie.
Die Pflichten für Allzweckmodelle gelten seit dem 2. August 2025. Modelle, die vorher auf dem Markt waren, haben bis zum 2. August 2027 Bestandsschutz, solange sie nicht grundlegend neu trainiert werden.
In vier Phasen zur eigenständigen KI
Unternehmen, die einen eigenständigen und von den USA unabhängigen KI-Einsatz anstreben, können das durch ein mehrstufiges Vorgehen erreichen. Dazu bietet sich ein Vier-Phasen-Modell an, das von der Bestandsaufnahme bis zu regelmäßigen Übungen für den Wechsel oder den Ausstieg reicht und das sich am Lebenszyklus von KI-Anwendungen orientiert. Dieser sieht insgesamt sieben Schritte vor:
- Schritt: Definition von KI-Einsatz und Anwendungen
- Schritt: Bewertung der KI-Anwendungen
- Schritt: Klärung von Verantwortung
- Schritt: Vorbereitung der Implementierung
- Schritt: Pilotbetrieb mit anschließender Freigabe
- Schritt: Betrieb mit regelmäßiger Prüfung
- Schritt: Außerbetriebnahme
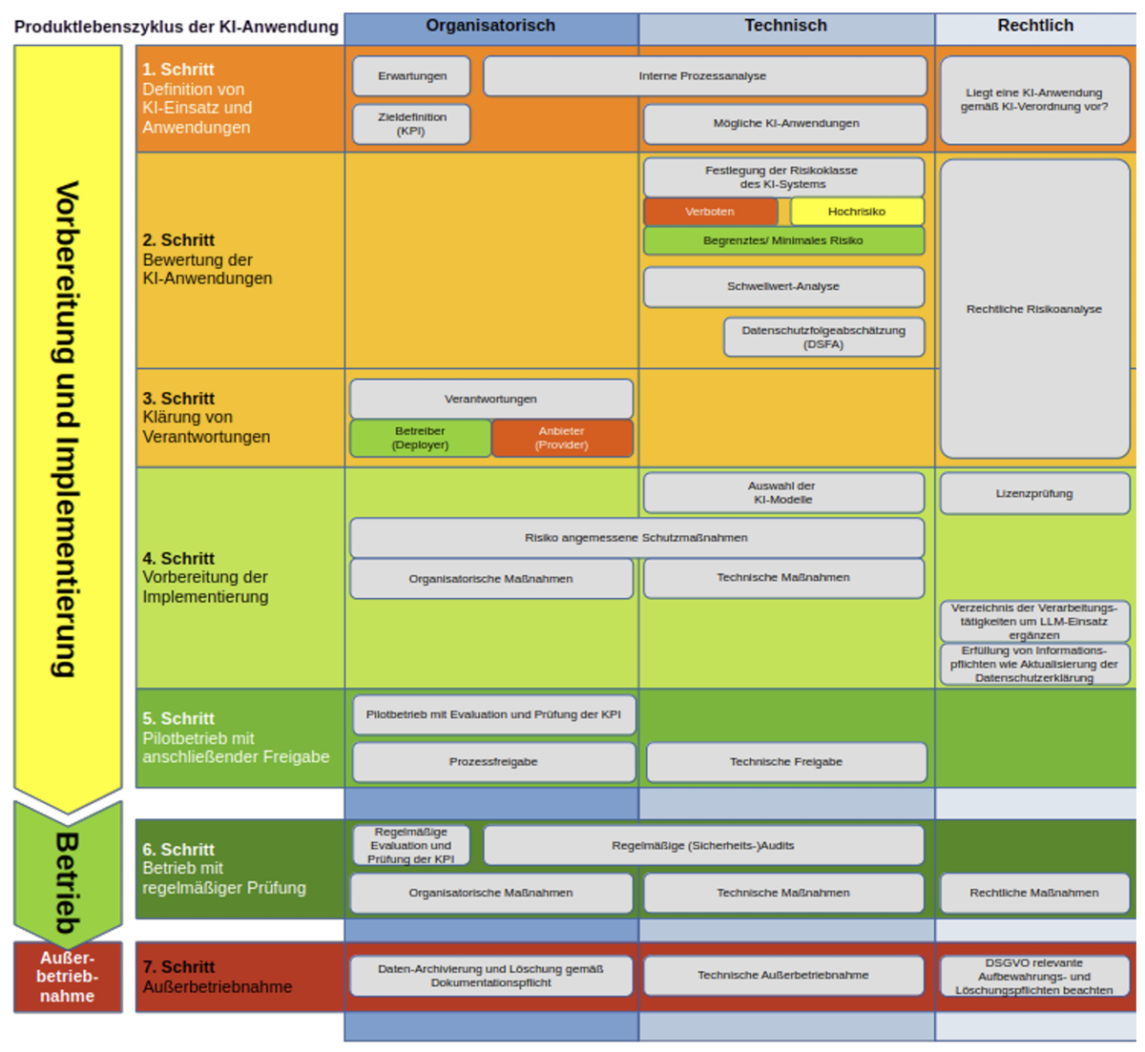
Abbildung: Lebenszyklus von KI-Anwendungen. Quelle: Allianz für Cyber-Sicherheit
Das Modell zur Inbetriebnahme einer eigenständigen und unabhängigen KI in Unternehmen verdichtet das auf vier Phasen:
Phase 1 – Bestand aufnehmen und einordnen
Zuerst kommt die ehrliche Inventur: Welche Cloud-Verträge, SaaS-Dienste und KI-Schnittstellen sind im Einsatz, und wo droht ein Lock-in? Parallel prüft das Unternehmen jeden geplanten KI-Fall rechtlich. Fällt er unter eine Hochrisikoklasse? Werden personenbezogene Daten verarbeitet, sodass eine Datenschutz-Folgenabschätzung nötig wird? Diese Klärung gehört an den Anfang, nicht ans Ende.
Phase 2 – Architektur standardisieren
Statt KI dezentral und unkontrolliert einzukaufen, zieht die IT eine eigene, anbieterunabhängige Zwischenschicht ein. Offene Virtualisierungs- und Container-Technik wie Proxmox statt VMware oder Kubernetes zur Orchestrierung macht die Architektur modular. So lässt sich das Modell im Hintergrund tauschen, ohne dass Fachanwendungen umgebaut werden müssen.
Phase 3 – Das KI-Gateway aufsetzen
Jetzt wird das Gateway als strenger Wächter in einer C3A-zertifizierten europäischen Cloud oder auf eigener Hardware in Betrieb genommen. Es bündelt alle Anfragen, wendet die Datenschutzregeln an und verteilt die Last auf die europäischen Modelle.
Phase 4 – Wissen aufbauen und den Ausstieg üben
Die wirksamste Maßnahme gegen Abhängigkeit ist Know-How im eigenen Haus. Teams sollten Open-Source-Technik, europäische Cloud-Architektur und den Umgang mit offenen Modellen beherrschen. In regelmäßigen Übungen muss das Unternehmen beweisen, dass es seine Daten verlustfrei aus einer US-Umgebung herausholen und in einem europäischen Rechenzentrum wieder zum Laufen bringen kann.
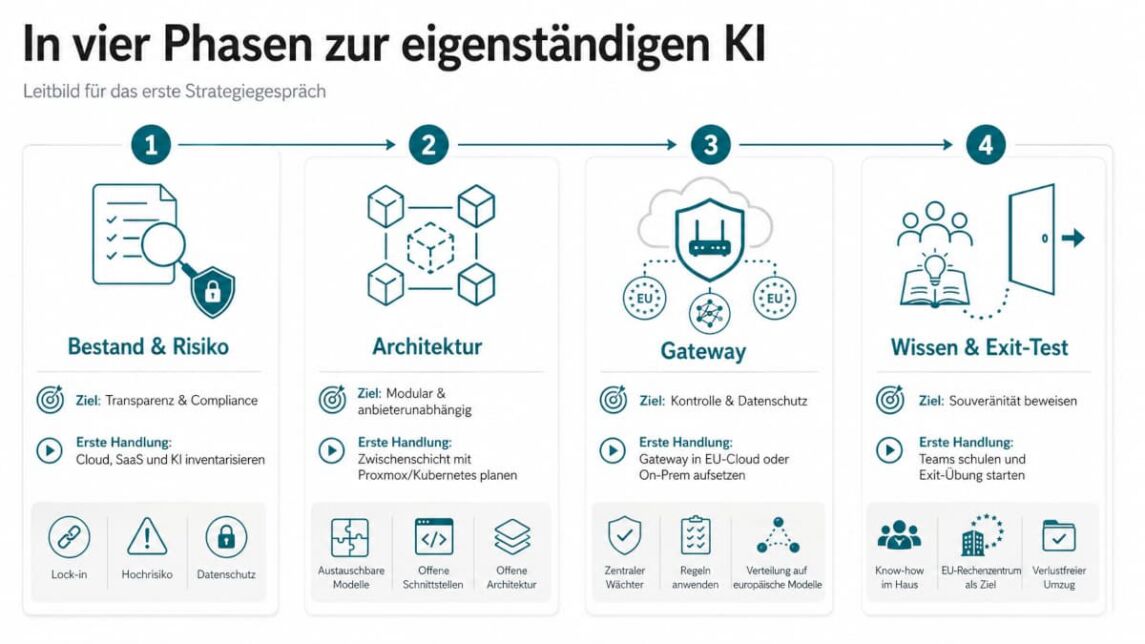
Abbildung: In 4 Phasen zur unabhängigen KI
KI-Unabhängigkeit in der Praxis
Die Abkehr von US-Abhängigkeit läuft bereits in mehreren Branchen.
Im Gesundheitswesen zählt jede Sekunde, und Patientendaten genießen höchsten Schutz. Das deutsche Unternehmen IDM beispielsweise hat mit ORPHEUS und ARGO Modelle entwickelt, die auf medizinisches Vokabular und das Erstellen von Arztbriefen trainiert sind und auf deutscher Infrastruktur laufen. Kein Krankenhaus muss dafür eigene Server betreiben. Mehrere Häuser teilen sich geprüfte europäische Cloud-Angebote, und die Zertifizierung nach ISO 13485 sorgt für Rechtssicherheit am Krankenbett.
In der Industrie versteht ein generischer US-Chatbot den Fachjargon des Maschinenbaus, CAD-Dokumente und Prozesslogik oft nicht zuverlässig. Genau dafür gibt es Soofi S, das auf souveräner Infrastruktur wie der Industrial AI Cloud der Telekom läuft. Mittelständler können solche Modelle mit ihren geheimen Konstruktionsplänen und Maschinendaten feinabstimmen, ohne dass diese Geheimnisse das Haus verlassen.
Dass souveräne KI im Alltag trägt, zeigt auch die Zusammenarbeit von Fraunhofer IAIS und EDEKA Hessenring, die gemeinsam eine KI-Roadmap für den Lebensmittelhandel auf eigener Infrastruktur erarbeiten.
In der öffentlichen Verwaltung steht die Handlungsfähigkeit des Staates auf dem Spiel. Eine Behörde darf bei Bürgeranliegen oder der Auslegung von Gesetzen nicht von Algorithmen abhängen, deren Regeln ohne demokratische Kontrolle anderswo gesetzt werden. Fraunhofer und Aleph Alpha entwickeln deshalb Assistenzsysteme, die Verwaltungsvorgänge nachvollziehbar automatisieren. Eine ausgezeichnete Lösung auf Basis agentischer KI verkürzt Genehmigungsverfahren von Monaten auf Tage und soll als quelloffene Blaupause an Bund, Länder und Kommunen weitergegeben werden.
Förderung: die Hürde für KMU sinkt
Der Aufbau einer eigenen unabhängigen KI kostet anfangs Geld und setzt den Aufbau von Wissen voraus. Gerade kleinere Unternehmen haben selten eine eigene Forschungsabteilung. Hier hilft ein dichtes Netz an Förderung. Der Bund hat seit 2019 mehr als 2,5 Milliarden Euro für KI gebunden, davon bereits über 490 Millionen ausgezahlt. Programme wie KI4KMU, KMU-innovativ oder das Zentrale Innovationsprogramm Mittelstand (ZIM) federn das Risiko von Entwicklungsvorhaben ab. Bei der Vergabe achten die Gutachter ausdrücklich darauf, dass ein Projekt die digitale Souveränität stärkt.
Praktische Hilfe vor Ort leisten die Mittelstand-Digital Zentren. In geschützten Laboren, etwa beim Zentrum Fokus Mensch in Stuttgart oder an Standorten in Lingen, Bremen, Kaiserslautern und Darmstadt, können Unternehmen KI-Lösungen ausprobieren, bevor sie diese teuer ins eigene System überführen.
Auf übergeordneter Ebene schaffen Gaia-X und Civic Coding vertrauenswürdige Datenräume, in denen sich Firmen, Verwaltungen und Forschung vernetzen und gemeinsam Modelle trainieren können, ohne die Kontrolle über ihre Daten abzugeben. Dass das funktioniert, hat das Training von Teuken-7B im Gaia-X-Umfeld gezeigt.
Worauf es ankommt
Eine eigenständige KI-Strategie für Unternehmen ist heute machbar. Sie sichert Verhandlungsmacht gegenüber Anbietern, schützt Geschäftsgeheimnisse vor fremdem staatlichen Zugriff und macht das Unternehmen zu einem verlässlichen Partner in einer unruhigen Weltlage. Offene Standards, ein KI-Gateway als Schaltzentrale, europäische Modelle auf souveräner Cloud und ein Team, das auch den Ausstieg beherrscht, sind die wichtigsten Zutaten.
Häufige Fragen (FAQs)
Müssen wir jetzt komplett auf US-KI verzichten?
Nein. Das Ziel ist Kontrolle. Solange Sie jederzeit wechseln können, ohne dass der Betrieb leidet, dürfen US-Dienste Teil des Werkzeugkastens bleiben. Entscheidend ist, dass kritische Prozesse nicht fest mit einem einzigen Anbieter verdrahtet sind und dass ein getesteter Ausstiegsplan existiert.
Sind europäische Modelle wirklich gut genug für unseren Betrieb?
Für die meisten Aufgaben ja. Mistral, Aleph Alpha, Teuken-7B und für die Industrie Soofi S decken ein breites Aufgabenfeld ab, und bei deutscher Sprache spielt Teuken-7B durch seinen sparsamen Tokenizer sogar einen Kostenvorteil aus. Bei Spezialdisziplinen wie Übersetzung (DeepL) oder Bildgenerierung (Black Forest Labs) gehören europäische Anbieter zur Weltspitze.
Lohnt sich der Umstieg für ein kleines oder mittleres Unternehmen?
Oft schon. Ein offenes Modell kostet wenig und liefert für interne Aufgaben gute Ergebnisse. Förderprogramme wie KI4KMU oder ZIM übernehmen einen Teil des Risikos, und die Mittelstand-Digital Zentren lassen Sie kostenlos testen, bevor Sie investieren.
Wie fangen wir an?
Mit der Bestandsaufnahme. Listen Sie auf, welche KI-Dienste im Haus laufen und wo ein Wechsel heute teuer wäre. Ordnen Sie parallel jeden Anwendungsfall rechtlich ein. Als schnellen ersten Schritt können Sie ein kleines Modell lokal aufsetzen oder einen europäischen Gateway-Dienst testen, um Erfahrung zu sammeln, bevor Sie die Architektur in der Breite umstellen.
Macht uns der EU AI Act das Leben schwer?
Für die meisten internen Anwendungen nicht. Das Gesetz richtet sich nach dem Risiko des konkreten Einsatzes, und Wissensmanagement oder Textentwürfe fallen in niedrige Klassen. Für offene Modelle in unkritischen Fällen gibt es zudem eine Ausnahme von vielen Pflichten. Heikel wird es erst bei Hochrisiko-Einsätzen wie automatischer Personalauswahl, die Sie deshalb früh als solche erkennen und gesondert behandeln sollten.
Ihr Wartungsspezialist für alle großen Hardware Hersteller
Durch Jahrzehnte lange Erfahrung wissen wir worauf es bei der Wartung Ihrer Data Center Hardware ankommt. Profitieren Sie nicht nur von unserer Erfahrung, sondern auch von unseren ausgezeichneten Preisen. Holen Sie sich ein unverbindliches Angebot und vergleichen Sie selbst.
Weitere Artikel

Berlin, Frankfurt oder München: Wo lohnt sich Co-Location in Rechenzentren noch?
Die RZ-Standorte Frankfurt, Berlin / Brandenburg und München halten für Co-Location verschiedene Stärken und Schwächen bereit. Wer derzeit auf dem

Google I/O: Gemini Omni & Flash 3.5 — und warum Search jetzt umgebaut wird
Shownotes Die grosse These Google verschiebt KI vom Einzelprodukt zum Betriebssystem-Prinzip: Search, Modelle und Agentenlogik greifen ineinander. Wer

ChatGPT Finance: Sollte man der KI Zugang zu seinen Bankkonten geben?
Das neue ChatGPT Finance verspricht Unterstützung bei der Verwaltung der Finanzen. Die Risiken der Nutzung sind allerdings erheblich. OpenAI hat
