


Wir zeigen, welche 8 Open-Source-KI-Modelle aktuell für Unternehmen besonders attraktiv sind.
Was in der KI-Landschaft lange Zeit als gesetzt galt, nämlich dass proprietäre, geschlossene Modelle von OpenAI, Anthropic oder Google technologisch unerreichbar sind, stimmt so nicht mehr. Der Stanford AI Index Report 2026 dokumentiert eine Angleichung der Leistungen von KI-Modellen, die noch vor zwei Jahren undenkbar schien: Die vier führenden KI-Anbieter trennen auf den globalen Arena-Leaderboards gerade einmal 25 Elo-Punkte. Open-Source-Modelle spielen längst in der gleichen Liga wie ihre teuren, verschlossenen Konkurrenten.
Für Unternehmen eröffnen sich damit attraktive Möglichkeiten, die bisher so noch nicht denkbar waren. Die eigentlichen Auswahlkriterien heißen heute: Betriebskosten, Datensouveränität, DSGVO-Konformität und fachliche Spezialisierung. Die Zeit des einen Universalmodells, das alle Unternehmensaufgaben erledigt, ist vorbei. Was zählt, ist das richtige Modell für den richtigen Einsatzbereich.
Methodik und Bewertungskriterien
Um eine praxisnahe Rangliste zu erstellen, haben wir fünf Kernkriterien definiert. Die Gewichtung orientiert sich an den tatsächlichen Anforderungen von IT-Architekten und Compliance-Verantwortlichen.
| Bewertungskriterium | Gewichtung | Beschreibung und Metriken |
| Logik, Code-Generierung & Agentik | 30 % | Moderne Benchmarks wie SWE-bench Verified, GPQA Diamond und Tau2-Bench. Ein hoher Score bedeutet überlegene Fähigkeiten bei komplexen Iterationen und Code-Verständnis. |
| Effizienz & Hardware-Infrastruktur | 20 % | Tokens pro Sekunde und Latenz (Time to First Token). Dazu die realen Hardware-Anforderungen für lokales Self-Hosting. |
| Datensicherheit, Governance & Lizenz | 20 % | Widerstandsfähigkeit gegen Prompt Injections, Lizenzfreiheit und geopolitische Compliance-Risiken. |
| Spezialisierung & Kontextgröße | 15 % | Kontextfenster bis zu 10 Millionen Tokens, RAG-Fähigkeit, native Multimodalität und Edge-Eignung. |
| Total Cost of Ownership (TCO) & ROI | 15 % | API-Kosten pro Million Tokens sowie die Wirtschaftlichkeit beim lokalen Betrieb. |
Tabelle 1: Bewertungskriterien und Gewichtungen für Open-Source-KI-Modelle. Jedes Modell wird auf einer Skala von 0 bis 10 Punkten bewertet. Der finale Score ergibt sich aus der gewichteten Summe: (Logik × 0,30) + (Effizienz × 0,20) + (Sicherheit × 0,20) + (Spezialisierung × 0,15) + (TCO × 0,15).
| Rang | Modell | Logik & Code (30%) | Effizienz & HW (20%) | Sicherheit & Lizenz (20%) | Spezialisierung (15%) | TCO & ROI (15%) | Finaler Score | Empfohlene Hauptbranche |
| 1 | Mistral Medium 3.5 | 8,0 | 7,0 | 9,0 | 8,0 | 8,0 | 8,00* | Softwareentwicklung, EU-Konzerne |
| 2 | DeepSeek V4 Pro | 10,0 | 4,0 | 8,0 | 9,0 | 8,0 | 7,95 | Finanzwesen, Tech-Infrastruktur |
| 3 | Nemotron Cascade 2 | 8,0 | 8,0 | 8,0 | 7,0 | 8,0 | 7,85 | Industrie, Robotik, Automobil |
| 4 | Gemma 4 (E4B) | 6,0 | 10,0 | 7,0 | 6,0 | 10,0 | 7,60 | IoT, Mobile Health, Edge-Computing |
| 5 | Phi-4-reasoning | 7,0 | 10,0 | 5,0 | 7,0 | 9,0 | 7,50 | EdTech, Visuelle RPA, Desktop |
| 6 | GLM-5.1 | 9,0 | 3,0 | 9,0 | 8,0 | 5,0 | 7,05 | IT-Consulting, Proprietäres Fine-Tuning |
| 7 | Kimi K2.6 | 8,0 | 4,0 | 7,0 | 10,0 | 6,0 | 7,00 | DevOps, Legacy-Code-Migrationen |
| 8 | Qwen 3.5 (397B) | 9,0 | 3,0 | 7,0 | 8,0 | 6,0 | 6,80 | Globale Logistik, Asiatische Übersetzungen |
| - | Llama 4 Scout | 7,0 | 8,0 | 6,0 | 10,0 | 9,0 | 7,75 | E-Commerce, IT-Monitoring |
| - | Llama 4 Maverick | 9,0 | 5,0 | 8,0 | 9,0 | 7,0 | 7,70 | Legal Tech, Gesundheitswesen, Compliance |
Tabelle 2: Die 8 besten Open-Source-KI-Modelle für Unternehmen. Anmerkung zur Sortierung: Mistral Medium 3.5 gewinnt das Enterprise-Ranking durch seine ausgewogene Leistung über alle Metriken hinweg. Giganten wie Qwen 3.5 und GLM-5.1 werden trotz hoher Intelligenz wegen ihrer Hardware-Anforderungen und TCO-Werte abgewertet. Wegen fehlender EU-Lizenz wurden die Meta Modelle der Llama-4-Familie nicht platziert.
Die 8 besten Open-Source-Modelle im Detail
1. Mistral Medium 3.5
Mistral Medium 3.5 kommt aus Frankreich und verfolgt einen anderen Ansatz als die Wettbewerber bei dem Mixture-of-Experts-Modellen: ein dichtes Modell mit 128 Milliarden Parametern, welches das Befolgen von Instruktionen, logisches Reasoning und Programmieren in einer einzigen Gewichtsmatrix vereint. Das Ziel sind sogenannte „Vibe Remote Agents“: Das sind asynchrone Programmierer-Agenten, die nahtlos in Unternehmenstools wie GitHub, GitLab, Linear und Jira integriert werden können. Entwickler starten über die Kommandozeile Aufgaben, die der KI-Agent autonom in einer Cloud-Umgebung abarbeitet, während der menschliche Kollege sich anderen Projekten widmet. Das Modell erreicht 77,6 % auf SWE-bench Verified und bietet ein 256K-Kontextfenster für komplexe Repositories.
Geeignet für: Europäische Großkonzerne, die Automobilindustrie und Software-Dienstleister. Wegen der Datenhaltung innerhalb der EU und der Herkunft aus Frankreich ideal für Organisationen mit strikten DSGVO-Anforderungen, die auf Spitzen-KI bei der Code-Generierung trotzdem nicht verzichten wollen.
Zu beachten: Als dichtes Modell ist der VRAM-Bedarf höher als bei vergleichbaren MoE-Architekturen. Für produktiven On-Premise-Betrieb werden mindestens zwei bis vier NVIDIA H100 GPUs benötigt. Die modifizierte MIT-Lizenz sollte vor dem Einbetten in skalierbare SaaS-Produkte rechtlich geprüft werden.
2. DeepSeek V4 Pro
DeepSeek V4 Pro ist technologisch das derzeit fortschrittlichste Open-Weight-Modell für Code und Mathematik. Die Architektur umfasst 1,6 Billionen Parameter insgesamt, von denen 49 Milliarden pro Token aktiv berechnet werden: ein klassisches Mixture-of-Experts-Prinzip also. Eine echte Innovation steckt im Aufmerksamkeitsmechanismus: Durch die Kombination von Compressed Sparse Attention und Heavily Compressed Attention reduziert DeepSeek den KV-Cache-Bedarf um 90 % und den Rechenaufwand um 27 % gegenüber der Vorgängerversion. Das macht das Kontextfenster von einer Million Tokens wirtschaftlich nutzbar. Das Modell steht unter der MIT-Lizenz und erreicht laut dem Center for AI Standards and Innovation 80,6 % auf SWE-bench Verified und 90,1 % im GPQA Diamond Benchmark. Und das bei Kosten, die in vielen Tests über 50 % unter denen der Konkurrenz liegen.
Geeignet für: Quantitativen Finanzsektor, algorithmischen Handel, Forschungseinrichtungen und große Software-Engineering-Abteilungen. Bei Coding-Benchmarks wie LiveCodeBench (93,5) und Codeforces ELO (3206) führt es das Feld an.
Zu beachten: Self-Hosting ist hardwareintensiv: mindestens acht NVIDIA H200 GPUs sind für das volle Kontextfenster bei FP8-Quantisierung nötig. Dazu kommt ein ernstes Compliance-Risiko: Berichte der U.S.-China Economic and Security Review Commission deuten darauf hin, dass DeepSeek möglicherweise durch koordinierte Angriffe auf US-Modelle trainiert wurde.
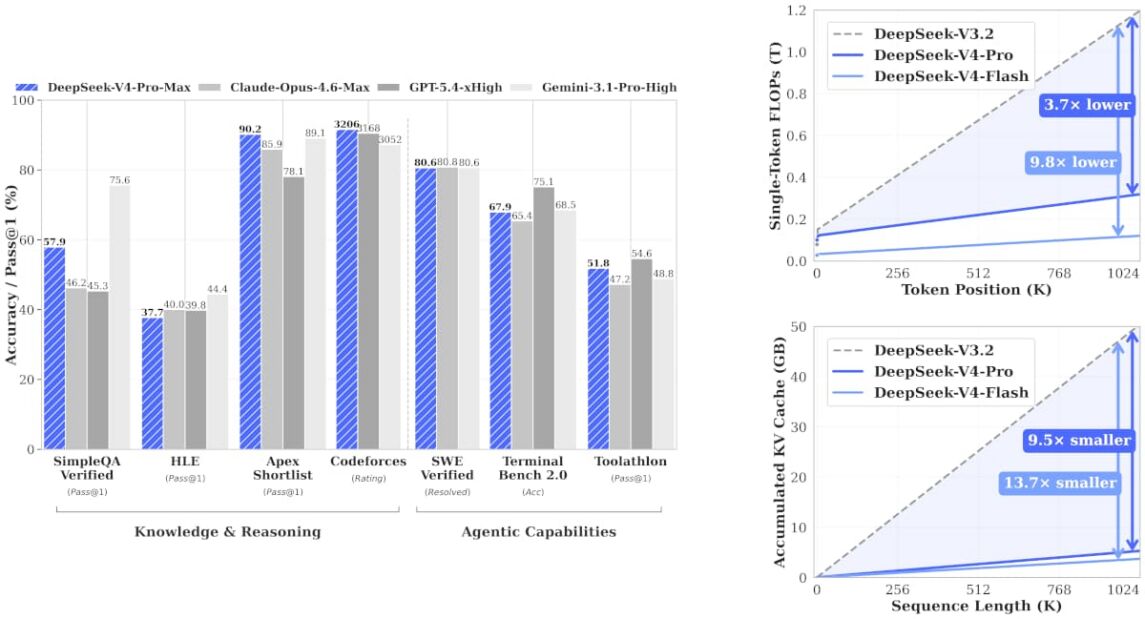
Abbildung 1: Benchmarks DeepSeek V4 Pro Max Benchmarks im Vergleich. Quelle: Hugging Face
3. Nemotron Cascade 2 (30B A3B)
NVIDIAs Nemotron Cascade 2 ist ein dichtes 30-Milliarden-Parameter-Modell, das auf maximale Effizienz im Edge- und On-Premise-Betrieb ausgelegt ist. Trotz seiner vergleichsweise geringen Größe erreicht es im GPQA-Benchmark herausragende 75,8 % und übertrifft damit zahlreiche deutlich schwerere Konkurrenten. Der operative Vorteil liegt in der nahtlosen Einbindung ins NVIDIA-Ökosystem: NeMo-Run, OmegaConf und die Xenna Pipeline Observability für lückenloses Artifact Tracking sind direkt integriert. Auf Consumer-Hardware wie RTX 4090 Clustern läuft das Modell mit über 54 Tokens pro Sekunde.
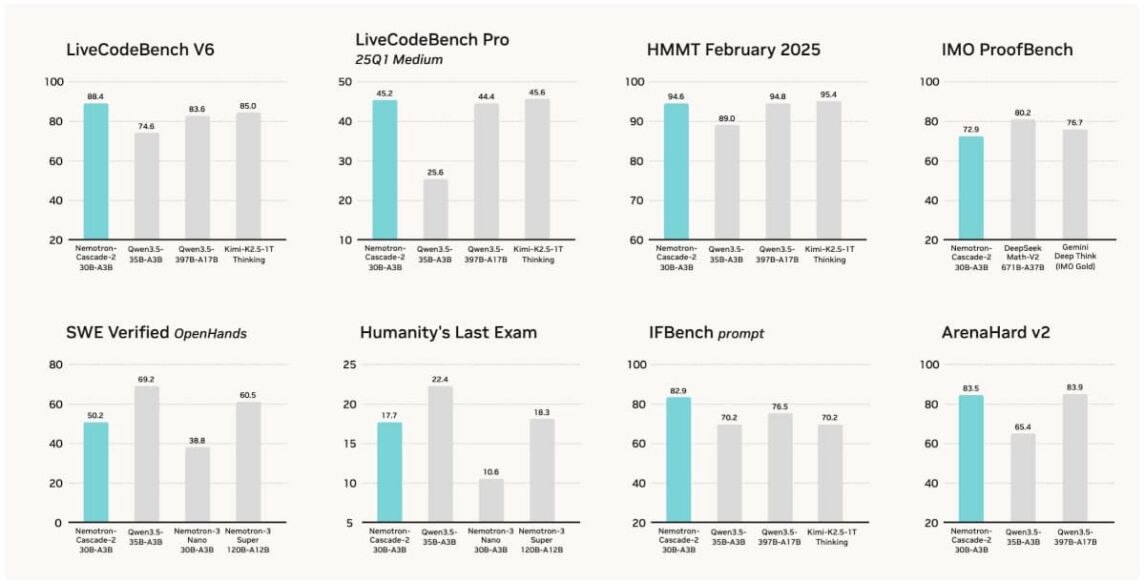
Abbildung 2: Nemotron Cascade 2 im Benchmark-Vergleich. Quelle: Hugging Face
Geeignet für: Produzierendes Gewerbe, Robotik, Automobilzulieferer und Unternehmen, die bereits tief im NVIDIA-Stack verwurzelt sind. Ideal für Edge-to-Cloud-Industrieanwendungen, bei denen schnelle lokale Entscheidungen direkt auf Werkshallenniveau getroffen werden müssen.
Zu beachten: Wegen der 30-Milliarden-Parameter-Grenze ist das enzyklopädische Weltwissen begrenzt. Das Modell sollte daher innerhalb einer strukturierten RAG-Pipeline eingesetzt werden, bei der das nötige Faktenwissen aus externen Unternehmensdatenbanken dynamisch nachgeladen wird.
4. Gemma 4 (E4B / E2B)
Google DeepMind bricht mit Gemma 4 radikal mit dem Prinzip, dass KI zwingend auf Server-Clustern laufen muss. Die Edge-Varianten E2B (ca. 2,3 Milliarden Parameter) und E4B (ca. 4,5 Milliarden Parameter) wurden ausdrücklich für den Betrieb auf Smartphones, IoT-Geräten und Laptops entwickelt, basierend auf Googles MediaPipe- und LiteRT-Stack. Eine technologische Leistung ist die native Verarbeitung von Audio, Bild und Text: Sprachbefehle lassen sich verarbeiten, ohne vorher einen fehleranfälligen Transkriptionsschritt durchzuführen. Die E4B-Variante benötigt in quantisierter Form nur 2,5 GB Festplattenspeicher und 4 bis 5 GB RAM.
Geeignet für: Medizintechnik, Mobile-Health-Anwendungen, IoT und den Außendienst. Das Modell ist die erste Wahl überall dort, wo sensible Nutzerdaten wie etwa medizinische Parameter oder Stimmdaten das physische Gerät niemals verlassen dürfen.
Zu beachten: Diese Modelle sind nicht für mehrstufige Agenten-Workflows oder komplexe Backend-Programmierung ausgelegt. Ihre Stärke liegt in latenzfreier, lokaler Interaktion und der Offline-Bereitstellung grundlegender Logik.
5. Microsoft Phi-4-reasoning
Microsoft verfolgt mit Phi-4-reasoning einen ungewöhnlichen Ansatz: Das visuell-multimodale Modell umfasst nur 14 bis 15 Milliarden Parameter, wurde aber durch intensives Supervised Fine-Tuning und nachgelagertes Reinforcement Learning auf extreme logische Tiefe trainiert. Anstatt Fakten zu speichern, generiert Phi-4 ausführliche logische Ketten und macht so optimalen Gebrauch von Rechenzeit beim Schlussfolgern. Das Ergebnis sind Leistungen in Mathematik, Wissenschaft und Algorithmen, die weit größere Modelle überbieten. Der VRAM-Bedarf liegt quantisiert bei durchschnittlich nur 7,1 GB.
Geeignet für: EdTech, Forschungsinstitute, Desktop-Assistenzsysteme und Software-Spezialisten. Dank ausgeprägtem räumlichem Verständnis für Bildschirminhalte (UI-Grounding) eignet sich Phi-4 besonders für automatisierte Software-Tests auf Basis visueller Screenshots.
Zu beachten: Microsoft spricht explizite Warnungen für hochriskante Bereiche aus: Medizinische Diagnosen, juristische Beratung und autonome Finanztransaktionen ohne menschliche Überwachung sind ausgeschlossen. Die Trainingsbasis ist primär englischsprachig. Bei anderen Sprachen muss mit Leistungseinbußen gerechnet werden.
6. GLM-5.1
GLM-5.1 von Z.ai ist ein gewaltiges MoE-System mit 744 Milliarden Parametern, wovon 40 Milliarden pro Inferenzschleife aktiv sind. Es läuft unter echter, unmodifizierter MIT-Lizenz – maximale rechtliche Freiheit für Unternehmen. Bei SWE-Bench Pro hielt GLM-5.1 zum Veröffentlichungszeitpunkt den State-of-the-Art-Rekord (58,4) und greift damit proprietäre US-Modelle wie GPT-5.4 direkt an.
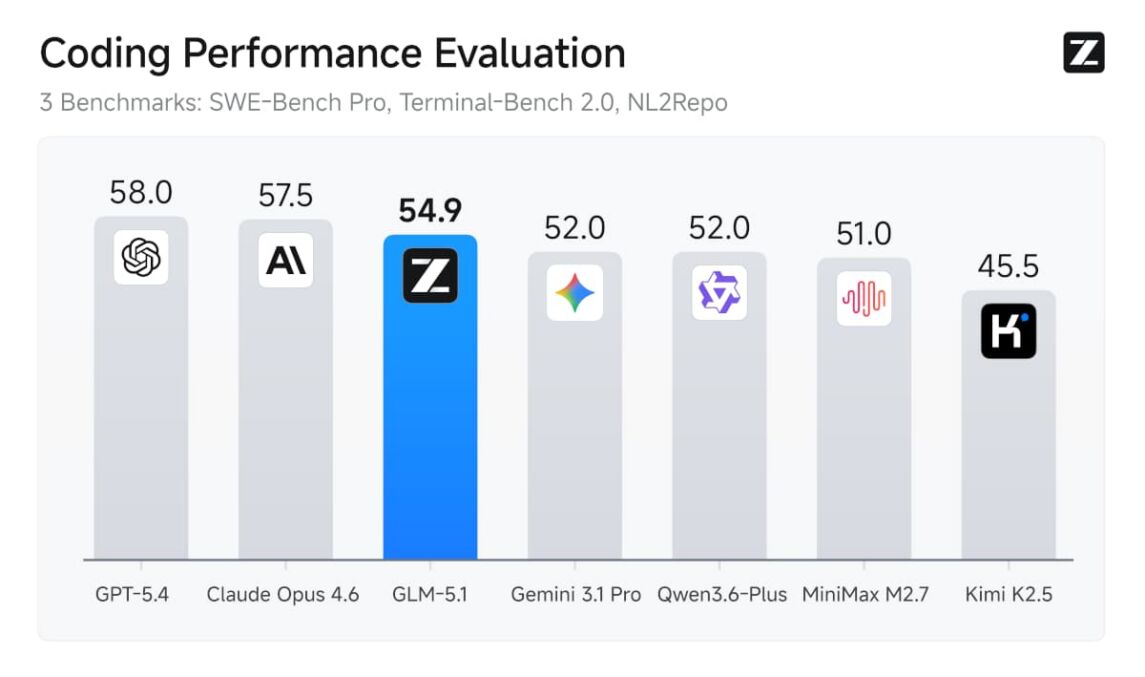
Abbildung 3: GLM-5.1 Coding Performance im Vergleich. Quelle: Ollama.com
Geeignet für: Internationale IT-Consulting-Häuser und dedizierte Software-Entwicklungszentren. Dank uneingeschränkter MIT-Lizenz lässt sich GLM-5.1 auf hochsensible interne Frameworks oder proprietäre Codebasen feinabstimmen, ohne Lizenzrestriktionen befürchten zu müssen.
Zu beachten: Die Systemanforderungen sind enorm. Um das Modell in FP16-Quantisierung zu laden, werden über 1.720 GB VRAM benötigt. Das entspricht 109 RTX 4090 GPUs oder 27 NVIDIA H100 GPUs. Für ein Minimal-Setup ist mindestens ein NVIDIA HGX B200 System erforderlich. Die meisten Unternehmen werden GLM-5.1 daher über Cloud-Infrastrukturen anbinden müssen.
7. Moonshot Kimi K2.6
Moonshot AIs Kimi K2.6 ist ein riesiges Open-Weight-Modell mit einer Billion Parametern, von denen 32 Milliarden pro Token aktiv sind. Die besondere Stärke liegt in der Orchestrierung massiver Agenten-Schwärme: Das Modell kann bis zu 300 Sub-Agenten parallel steuern und hat in internen Tests über 4.000 Werkzeugaufrufe in einer zwölfstündigen autonomen Ausführung abgesetzt.
Geeignet für: Cloud-Architekten, DevOps-Ingenieure und Migrations-Spezialisten. Besonders wertvoll für Organisationen, die alte Legacy-Codebasen analysieren, automatisch in moderne Sprachen wie Rust oder Go portieren und gleichzeitig dokumentieren lassen wollen.
Zu beachten: Für einfache Chatbots oder schnelle Code-Autovervollständigung ist dieses Modell Overkill. Die Bereitstellung von 300 parallelen Agenten über Stunden erzeugt immense Rechenkosten. Die asiatische Herkunft erfordert die üblichen Compliance-Prüfungen zur Datensouveränität.
8. Qwen 3.5 (Flagship 397B-A17B)
Alibaba Clouds Qwen3.5-397B-A17B ist ein mächtiges Open-Weight-MoE-Modell unter der Apache-2.0-Lizenz. Von den 397 Milliarden Parametern werden durch Sparse-Routing lediglich 17 Milliarden pro Token aktiviert. Die hybride Attention-Architektur sorgt dafür, dass der KV-Cache selbst beim 256K-Kontextfenster nicht unkontrolliert wächst. Mit 86,7 auf Tau2-Bench und 88,0 auf MMLU-Pro operiert Qwen 3.5 auf absolutem Spitzenniveau.
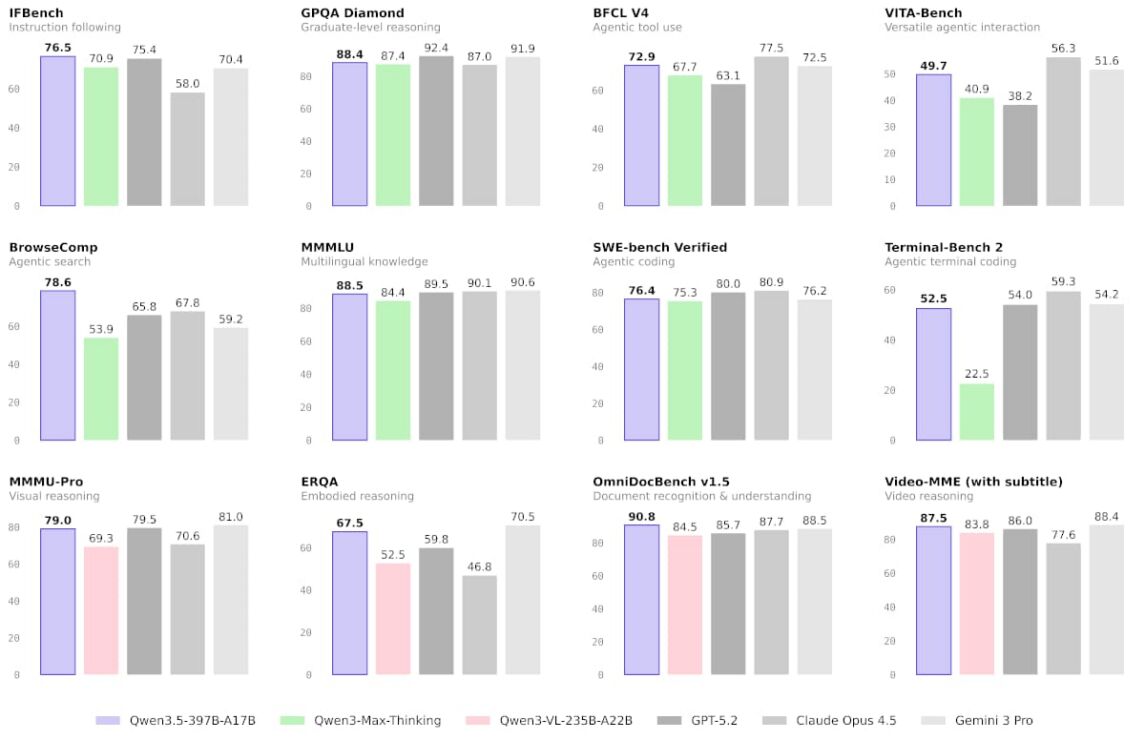
Abbildung 4: Qwen 3.5 397B-A17B Benchmarks im Vergleich
Geeignet für: Global agierende Logistikkonzerne, internationale Retailer und Übersetzungsagenturen. Das Modell beherrscht über 201 Sprachen und ist bei asiatischen Sprachen in Agenten-Pipelines derzeit konkurrenzlos.
Zu beachten: Trotz effizienter Architektur sind die Hardware-Anforderungen für kleinere Unternehmen kaum tragbar. Selbst in INT4-Quantisierung bindet das Modell über 230 GB VRAM. Für performanten Betrieb ist ein Cluster von vier bis acht NVIDIA H100 oder H200 GPUs nötig. Außerdem bestehen geopolitische Compliance-Risiken ähnlich wie bei DeepSeek.
Außer Konkurrenz: Llama 4
Weil Llama 4 von Meta aufgrund der Lizenzbestimmungen zumindest derzeit nicht in der EU genutzt werden darf, haben wir es nicht in die Liste aufgenommen. Aufgrund seiner Leistung möchten wir es aber dennoch kurz vorstellen.
Llama 4 Maverick
Meta hat mit der Llama-4-Serie auf Mixture-of-Experts umgestellt und damit einen Meilenstein für multimodale Unternehmens-KI gesetzt. Maverick, das Flaggschiff der Serie, hat 400 Milliarden Parameter (17 Milliarden davon aktiv pro Token) und greift auf 128 Expertennetzwerke zurück. Die „Early Fusion“-Architektur speist visuelle Tokens direkt in den Transformer-Kern ein – das ermöglicht echte, native Multimodalität ohne fehleranfällige Umwege. Bei der Extraktion komplexer Klauseln aus juristischen Verträgen erzielte Maverick in Enterprise-Evaluationen 85 bis 92 % Genauigkeit. Kleinere Modelle lagen weit darunter.

Abbildung 5: Llama-4-Familie. Quelle: Meta
Geeignet für: Juristischen Sektor, Compliance-Abteilungen, Versicherungswesen und Gesundheitssektor. Ideal, wenn es darum geht, große Mengen unstrukturierter juristischer oder regulatorischer Dokumente zu analysieren.
Zu beachten: Die Llama-Lizenz erlaubt kommerzielle Nutzung, verlangt aber eine gesonderte Vereinbarung mit Meta, sobald 700 Millionen monatlich aktive Nutzer überschritten werden. Im reinen Software-Engineering liegt Maverick deutlich hinter spezialisierten Modellen – LiveCodeBench zeigt nur 43,4 %.
Llama 4 Scout
Scout ist das kleinere Schwestermodell von Maverick: 109 Milliarden Parameter insgesamt, 17 Milliarden aktiv, 16 Expertennetzwerke. Die eigentliche Alleinstellung ist das Kontextfenster: Scouts iRoPE-Architektur ermöglicht 10 Millionen Tokens – ein Weltrekord unter aktuellen Modellen. Dazu kommen eine hohe Geschwindigkeit (bis zu 2.600 Tokens pro Sekunde, Latenz von 0,33 Sekunden) und sehr niedrige API-Kosten von 0,08 Dollar pro Million Input-Tokens.
Geeignet für: Telekommunikation, E-Commerce, IT-Infrastruktur-Monitoring. Scout ist das optimale Modell, wenn RAG-Systeme gigantische Logfiles, jahrelange Kundenhistorien oder ganze Buchbestände ohne Vorauswahl in einem einzigen Prompt verarbeiten sollen.
Zu beachten: Die Geschwindigkeit erkauft sich Scout mit logischer Tiefe. Bei komplexen juristischen Extraktionen fiel die Genauigkeit auf 45 bis 70 % ab. Noch wichtiger: Sicherheitsanalysen von Protect AI zeigen eine Attack Success Rate von 64,1 % bei Prompt Injections. Ohne vorgeschaltete Sicherheitsfilter ist Scout in kundennahen Chatbots ein erhebliches Unternehmensrisiko.
Hardware: Das VRAM-Problem bleibt
Die größte Hürde bei der KI-Implementierung ist die Schere zwischen Parameterzahl und realen Betriebskosten. Der Wechsel von dichten Modellen hin zur Mixture-of-Experts-Architektur sollte Inferenz günstiger machen. Das VRAM-Problem bleibt dennoch bestehen.
Selbst wenn ein MoE-Modell wie Qwen 3.5 pro Token nur 17 Milliarden Parameter aktiviert, müssen die Gewichte aller 397 Milliarden Parameter permanent im GPU-Speicher vorgehalten werden, denn sonst steigt die Latenz ins Unzumutbare. Selbst bei INT4-Quantisierung erfordert Qwen 3.5 über 231 GB VRAM, noch ohne den Key-Value-Cache für große Kontextfenster. Das erzwingt Server-Farmen mit H100- oder H200-Beschleunigern, die für den normalen Mittelstand nicht finanzierbar sind.
Die Gegenbewegung läuft über Edge AI: Modelle wie Gemma 4 und Nemotron Cascade 2 verlagern die Rechenarbeit direkt auf die Endgeräte. Smartphones übernehmen die Rechenlast, Cloud-Kosten entfallen, Datenschutzvorgaben werden automatisch eingehalten. Für IT-Architekten bedeutet das eine klare Aufgabenteilung: Einfache Triage-Aufgaben und Audioverarbeitung gehören auf Edge-Geräte, komplexe Logik und riesige Kontextfenster auf dedizierte Server.
Geopolitik, Lizenz und Datensouveränität
Die Wahl eines KI-Modells ist keine rein technische Entscheidung. Chinesische Open-Source-Modelle wie DeepSeek V4 und Qwen 3.5 haben die Abhängigkeit von amerikanischen Anbietern spürbar reduziert und ermöglichen europäischer wie asiatischer Industrie den Aufbau eigener Systeme.
Die Fähigkeiten chinesischer Modelle wurden sehr wahrscheinlich durch groß angelegte „Distillation Attacks“ erworben: Über Proxy-Netzwerke wurden die Ausgaben amerikanischer Frontier-Modelle wie Claude oder GPT-5 in industriellem Maßstab abgeschöpft, um damit günstigere Open-Source-Modelle zu trainieren. Das verstößt gegen US-Exportkontrollen und gegen die Nutzungsbedingungen westlicher Anbieter.
Wenn Behörden Nutzungsverbote für Modelle aussprechen, die auf illegaler Datendestillation basieren, drohen Strafzahlungen oder ein sofortiger Architekturwechsel. Modelle mit klarer rechtlicher Herkunft wie Mistral Medium 3.5 aus Frankreich gewinnen dadurch strategisch an Gewicht, auch wenn sie in einzelnen Benchmarks punktuell schwächer abschneiden.
Die Lizenzlandschaft selbst ist stark fragmentiert: echte MIT-Lizenz bei DeepSeek und GLM, modifizierte kommerzielle Limits bei Llama, strikte Nutzungsbindungen bei Gemma und Kimi. Das erfordert einen sorgfältigen Prüfprozess durch die Rechtsabteilung.
3 Empfehlungen zum Schluss
Open-Source-KI liefert Unternehmen kognitive Fähigkeiten, die vor wenigen Monaten noch hinter teuren Paywalls verborgen waren. Modelle wie DeepSeek V4 Pro oder Mistral Medium 3.5 sind erstklassige Werkzeuge.
Drei Empfehlungen für die Praxis:
- Kein Universalmodell erzwingen. Einfache Aufgaben wie Triage, Sensorauswertung oder Offline-Sprachverarbeitung gehören auf Edge-Modelle wie Gemma 4 oder Nemotron Cascade 2. Nur wirklich komplexe Aufgaben wie Vertragsanalysen rechtfertigen den teuren Einsatz von Schwergewichten wie Mistral.
- Budgets in die Infrastruktur stecken, nicht nur in Modelle. Weil erstklassige Open-Source-Modelle nahezu kostenlos verfügbar sind, braucht es Investitionen in MLOps, Monitoring und Governance-Systeme. Autonome Agenten ohne Aufsicht schaffen beachtliche Risiken.
- TCO realistisch rechnen. Wer Self-Hosting mit MoE-Giganten wie Qwen oder GLM plant, muss den GPU-Cluster mitkalkulieren. Die Abschreibungskosten für H100-Farmen machen die Einsparungen gegenüber kommerziellen Cloud-APIs oft zunichte. Dichte Modelle der mittleren Gewichtsklasse wie Mistral sind häufig der wirtschaftlichere Kompromiss.
Der entscheidende Wettbewerbsvorteil 2026 besteht darin, ein sicheres, kosteneffizientes und datenschutzkonformes Ökosystem aufzubauen, in dem diese Modelle nahtlos zusammenarbeiten.
Ihr Wartungsspezialist für alle großen Hardware Hersteller
Durch Jahrzehnte lange Erfahrung wissen wir worauf es bei der Wartung Ihrer Data Center Hardware ankommt. Profitieren Sie nicht nur von unserer Erfahrung, sondern auch von unseren ausgezeichneten Preisen. Holen Sie sich ein unverbindliches Angebot und vergleichen Sie selbst.
Weitere Artikel

Google lädt KI auf deinen Rechner – und das ist erst der Anfang
️ Über diese Episode In dieser Folge sprechen Yusuf Sar und Christian Kunz über Edge AI, lokale KI-Modelle, Big-Tech-Earnings und Industrial AI.

Neue KI-Bildmodelle sorgen für mehr App-Downloads
Neue KI-Bild- und Videomodelle erweisen sind nach einer Auswertung von appfigures ein besonders starker Treiber für das Wachstum von KI-Apps.

Edge AI bevorzugt: Warum in der Industrie-KI die Cloud oftmals keine Lösung ist
In der Industrie ist Edge AI häufig die bessere Lösung gegenüber KI aus der Cloud. Das hat nicht nur Datenschutzgründe.
