


Wer ein Modell wie GPT, Claude oder Mistral so einsetzen möchte, dass es den eigenen Fachjargon beherrscht, juristisch sauber arbeitet und bezahlbar bleibt, muss sich die Frage stellen: Lohnt es sich, ein Modell mit eigenen Daten nachzutrainieren, also zu „fine-tunen“, oder gibt es smartere Wege? Wir zeigen, was Fine-Tuning von KI-Modellen leisten kann, welche regulatorischen Stolperfallen lauern und wie der Prozess konkret abläuft.
Drei Wege, ein Modell anzupassen
Bevor ein Unternehmen erhebliche Ressourcen in das Fine-Tuning eines Modells steckt, sollte klar sein, ob das überhaupt das passende Werkzeug ist. In der Praxis stehen drei Ansätze zur Verfügung, die unterschiedliche Ziele verfolgen und sich gut kombinieren lassen.
Prompt Engineering
Prompt Engineering ist die einfachste Variante. Das Modell wird ausschließlich über geschickt formulierte Eingaben gesteuert, etwa durch Beispiele, schrittweise Anweisungen oder bestimmte Rollendefinitionen. Die Gewichte des Modells bleiben unangetastet, es entstehen keine Trainingskosten, und Anpassungen sind innerhalb von Stunden machbar. Der Haken: Das Modell lernt nichts Neues dazu und bleibt auf den Wissensstand seiner ursprünglichen Trainingsdaten beschränkt.
Retrieval-Augmented Generation (RAG)
RAG geht einen anderen Weg. Das Sprachmodell wird mit einer externen Wissensdatenbank verknüpft, meist einer Vektordatenbank. Stellt jemand eine Frage, sucht das System zunächst die passenden Dokumente heraus und reicht sie dem Modell zur Beantwortung mit. Der größte Vorteil: Das Modell kann seine Quellen nennen, was in regulierten Branchen unverzichtbar ist.
Wirtschaftlich punktet RAG dort, wo sich Wissen häufig ändert, zum Beispiel bei Produktkatalogen, Handbüchern oder Compliance-Richtlinien. Ein Update bedeutet hier nur, Dokumente in der Datenbank auszutauschen, ganz ohne neues Training.
Fine-Tuning
Fine-Tuning ist der tiefgreifendste Eingriff. Ein vortrainiertes Basismodell wird mit einem kuratierten, domänenspezifischen Datensatz weiter trainiert, sodass sich seine internen Gewichte verändern.
Hier hält sich ein weit verbreiteter Irrtum: Fine-Tuning eignet sich nicht primär dazu, dem Modell neues Faktenwissen zu vermitteln. Fakten sind in den Parametern eines neuronalen Netzes schwer zu aktualisieren. Die wahre Stärke des Fine-Tunings liegt im Anpassen von Verhalten, Tonfall, Format und Aufgabenverständnis. Typische Einsatzfelder sind die hochvolumige Sentiment-Analyse, das Extrahieren juristischer oder medizinischer Entitäten oder die Klassifikation von Support-Tickets, also Fälle, in denen ein Modell eine eng definierte Aufgabe mit maximaler Präzision und minimaler Latenz erledigen soll.
Die drei Ansätze schließen einander nicht aus, ganz im Gegenteil. Die Verbindung aus feinabgestimmtem Modell und RAG hat sich in komplexen Domänen wie Medizin und Finanzberatung als Goldstandard etabliert. Das Fine-Tuning sorgt für Format, Jargon und Antwortstruktur, während RAG zur Inferenzzeit die tagesaktuellen Fakten liefert.
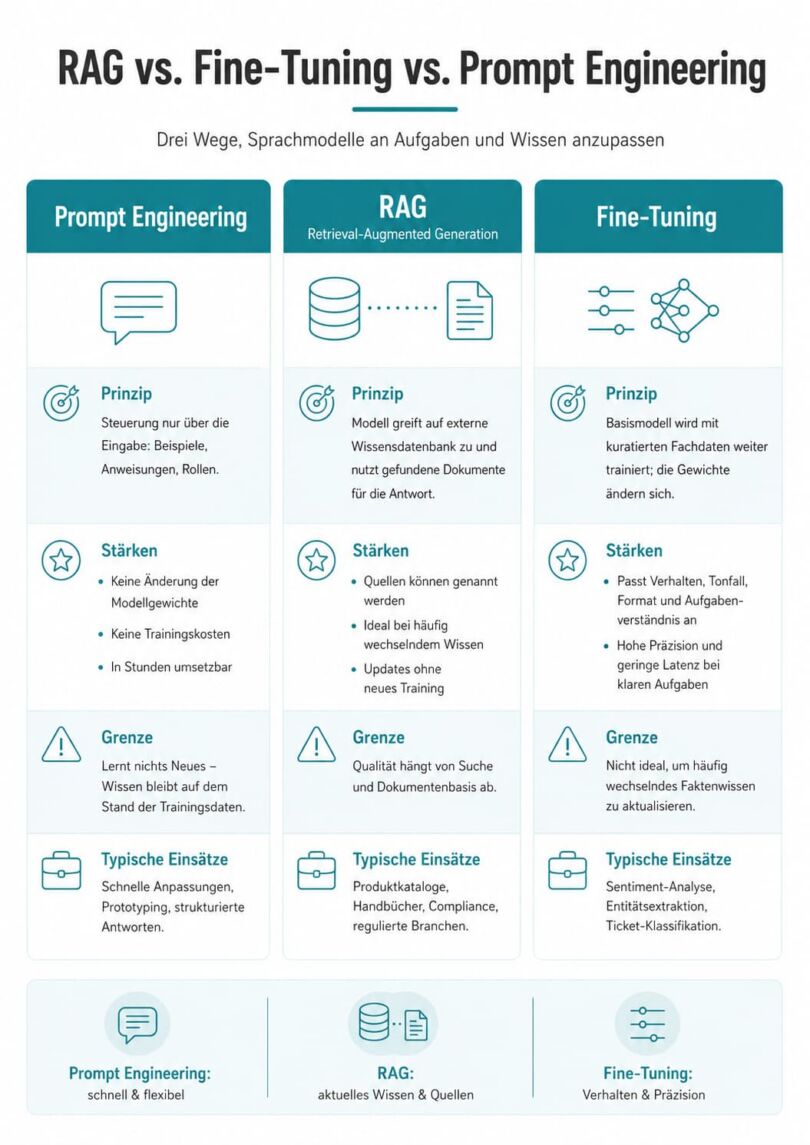
Abbildung 1: Prompt Engineering, RAG und Fine-Tuning im Vergleich
Als Faustregel gilt: Bei volatilem Wissen und hohen Anforderungen an Erklärbarkeit ist RAG die richtige Wahl. Bei stabiler Informationsbasis, sehr niedrigen Latenzanforderungen und einer klar definierten Aufgabe mit hohem Abfragevolumen spielt Fine-Tuning seine Stärken aus.
Compliance: Das regulatorische Minenfeld
Wer eigene Daten zum Fine-Tuning verwendet, muss in Europa eine Reihe von Vorschriften und Regulierungen beachten. Verstöße können teuer werden und das gesamte Projekt rechtlich gefährden.
DSGVO: Das Problem der „Modell-Memorisation“
Neuronale Netze lernen primär statistische Muster, können aber exakte Fragmente ihrer Trainingsdaten wortwörtlich reproduzieren. Dieses Phänomen heißt „Memorisation“ und steht im Widerspruch zu DSGVO-Grundrechten wie dem Auskunftsrecht (Art. 15) und dem Recht auf Löschung (Art. 17). Sind personenbezogene Daten einmal in den Modellgewichten verankert, lassen sie sich dort kaum noch selektiv entfernen.
Der Europäische Datenschutzausschuss (EDPB) hat in seiner Stellungnahme 28/2024 detaillierte Vorgaben für „Compliance-by-Design“ gemacht. Die Einwilligung scheidet als Rechtsgrundlage meist aus, weil sie widerrufbar sein müsste. Das ist technisch kaum machbar. In der Praxis stützen sich Unternehmen deshalb auf das berechtigte Interesse nach Art. 6 Abs. 1 lit. f DSGVO. Dafür ist ein dreistufiger Test verpflichtend:
- Es gibt ein legitimes Ziel wie etwa einen internen Support-Chatbot oder ein System zur Betrugserkennung.
- Erforderlichkeit: Lässt sich das Ziel auch mit anonymisierten oder synthetischen Daten erreichen? Dann scheidet der Einsatz personenbezogener Daten aus.
- Interessenabwägung: Die Grundrechte der Betroffenen dürfen nicht überwiegen.
Pflichtmaßnahmen sind eine strikte Anonymisierung, Pseudonymisierung und Data Masking. All das muss vor Beginn des Trainings geschehen.
Wichtig zu wissen: Ein Modell, das auf Aufforderung persönliche Trainingsdaten reproduziert, gilt rechtlich nie als anonymisiert und unterliegt vollständig der DSGVO. Hinzu kommt eine fast immer erforderliche Datenschutz-Folgenabschätzung (DPIA), die den gesamten Lebenszyklus abdecken muss, einschließlich Inference-Logs und Vektorspeicher.
EU AI Act: Wann aus dem Nutzer ein Provider wird
Eine besonders heikle Falle lauert im EU AI Act. Wer ein bestehendes Open-Source-Modell nur über eine API nutzt, gilt als „Deployer“ mit überschaubaren Transparenzpflichten. Wer das Modell aber tiefgreifend per Fine-Tuning verändert, kann zum „GPAI Modifier“ aufsteigen und damit zum Anbieter eines neuen General-Purpose-AI-Modells werden, mit deutlich höheren Pflichten.
Das EU AI Office hat im April 2025 mathematische Schwellenwerte definiert. Das zentrale Kriterium heißt “Ein-Drittel-Regel”. Beansprucht das Fine-Tuning mehr als ein Drittel der Rechenleistung, die für das ursprüngliche Pre-Training nötig war, gilt das Resultat als „distinktes neues Modell“. Das modifizierende Unternehmen muss dann eine eigenständige technische Dokumentation erstellen und eine Zusammenfassung der Trainingsdaten gemäß europäischem Urheberrecht öffentlich machen. Übersteigt der Trainingsaufwand bestimmte Schwellenwerte, entsteht sogar eine Einstufung als „systemisches Risiko“ mit Risikobewertungen, Adversarial Testing und Meldepflichten bei Sicherheitsvorfällen.
Diese Regeln gelten seit August 2025 für neu in Verkehr gebrachte Modelle. Verstöße werden mit bis zu 35 Millionen Euro oder sieben Prozent des weltweiten Jahresumsatzes geahndet.
Finanzsektor und Gesundheitswesen
Im deutschen Finanzsektor greifen zusätzlich Vorgaben der BaFin. Die Aufsichtsbehörde integriert KI ausdrücklich in die bestehenden Frameworks BAIT, VAIT und den europäischen Digital Operational Resilience Act (DORA). Im Januar 2026 hat die BaFin eine spezifische Orientierungshilfe zu IKT-Risiken beim KI-Einsatz veröffentlicht. Der Einsatz von LLMs muss Teil einer vom Vorstand genehmigten KI-Strategie sein. Cloud-Verträge brauchen klare Klauseln zu Sub-Outsourcing, Audit-Rechten und Exit-Strategien, und es müssen Verfahren zur sicheren Deinstallation veralteter Modelle existieren.
Im Gesundheitssektor überlagern sich der EU AI Act und die Medical Device Regulation (MDR). Eine im Mai 2026 veröffentlichte Roadmap von BfDI, Hessischem Ministerium und Bundesnetzagentur klärt eine wichtige Frist: Für KI-Systeme, die zugleich Medizinprodukte sind, gilt eine verlängerte Übergangsfrist bis August 2027. Hersteller müssen in klinischen Bewertungen lückenlos nachweisen, dass ihre Trainingsdaten statistisch robust und ethisch erhoben sind, häufig über unabhängige Datentreuhandstellen.
Technische Praxis: Fine-Tuning am Beispiel von Mistral 7B
Wie sieht das Ganze nun konkret aus? Nehmen wir das in Europa beliebte Open-Source-Modell Mistral 7B mit seinen sieben Milliarden Parametern. Das klassische Full Fine-Tuning würde riesige Mengen GPU-Speicher (VRAM) benötigen und ist auf gewöhnlicher Hardware schlicht nicht machbar. Die elegante Lösung heißt QLoRA (Quantized Low-Rank Adaptation), ein Verfahren des sogenannten Parameter-Efficient Fine-Tuning (PEFT).
Quantisierung: Das Modell schlanker machen
Im ersten Schritt wird das Modell nicht in seiner üblichen 16-Bit- oder 32-Bit-Präzision geladen, sondern auf 4 Bit quantisiert. Dieser Schritt reduziert den Speicherbedarf von rund 28 Gigabyte auf nur noch 7 Gigabyte VRAM. Damit das nicht zu Lasten der Modellqualität geht, kommen zwei mathematische Tricks zum Einsatz: der speziell für neuronale Netze optimierte Datentyp NF4 (Normal Float 4) und eine „Double Quantization“, bei der auch die Quantisierungskonstanten selbst nochmals komprimiert werden. Die eigentlichen Berechnungen während des Trainings laufen im präziseren bfloat16-Format ab, damit die Lernstabilität erhalten bleibt.
Der Clou von QLoRA: Die Milliarden Basisgewichte des Modells werden komplett eingefroren und nicht mehr verändert. Stattdessen werden winzige, trainierbare Rang-Zerlegungsmatrizen parallel zu den bestehenden neuronalen Schichten in die Architektur injiziert, typischerweise an den Attention- und Multi-Perceptron-Layern. Das Modell lernt nur noch, diese kleinen Zusatzmatrizen anzupassen. Die Zahl der trainierbaren Parameter sinkt damit um über 90 Prozent. Nach dem Training können diese kompakten Adapter entweder dauerhaft mit dem Basismodell verschmolzen oder zur Laufzeit dynamisch geladen werden.
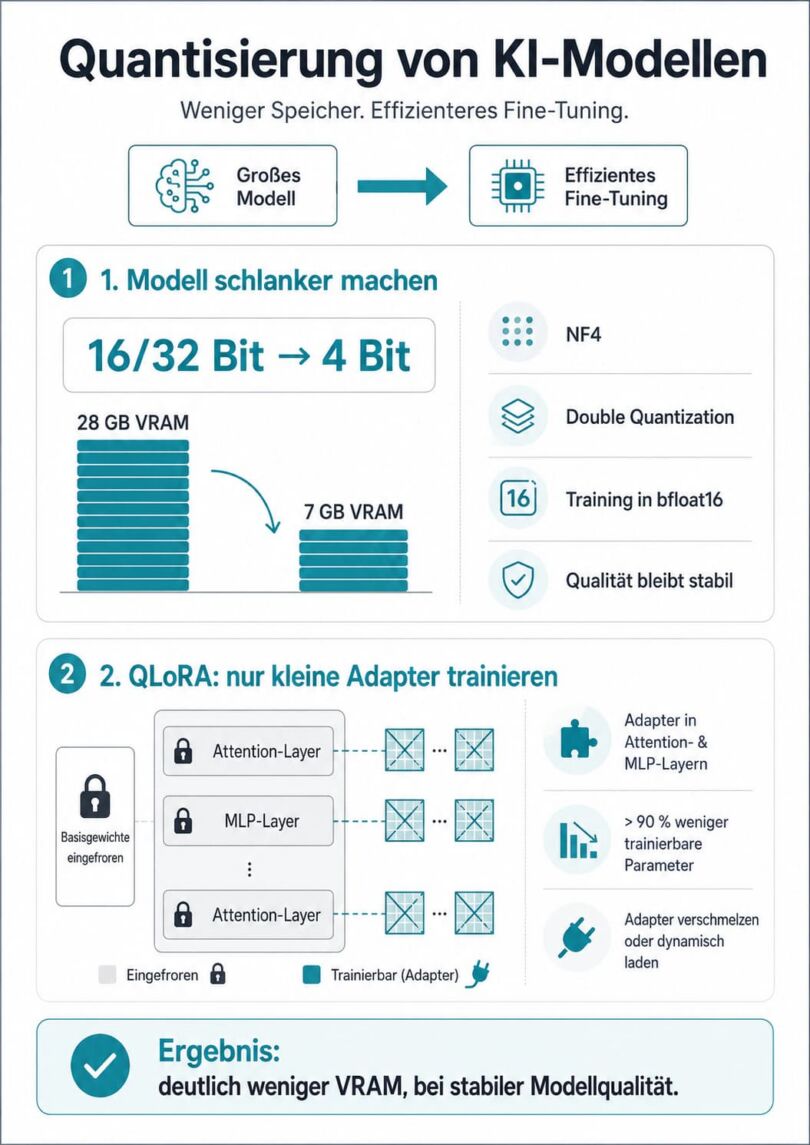
Abbildung 2: Quantisierung von KI-Modellen
Datenqualität schlägt Datenmenge
Die beste Architektur nützt wenig ohne saubere Daten. Hier gilt: „Quality beats Quantity“. Ein sorgfältig kuratierter Datensatz mit 500 bis 5.000 Beispielen, der die tatsächliche Aufgabenstellung präzise abbildet, schlägt einen Datensatz von 50.000 unstrukturierten Texten deutlich.
Bei Klassifikationsaufgaben muss auf eine ausgewogene Verteilung der Kategorien geachtet werden, bei generativen Aufgaben auf linguistische Vielfalt. Techniken wie Rückübersetzungen oder Synonym-Austausch helfen, kleinere Datensätze robuster zu machen.
Wie misst man, ob das Ergebnis gut ist?
Klassische Genauigkeits-Metriken aus dem Machine Learning greifen bei generativer KI zu kurz. Es gibt selten genau eine richtige Antwort. Das vom Stanford Center for Research on Foundation Models entwickelte Framework HELM (Holistic Evaluation of Language Models) hat sich als systematischer Maßstab durchgesetzt.
HELM bewertet Modelle entlang mehrerer Dimensionen:
- Intent Alignment
- Explanation Quality
- Interaction Naturalness
- Trust & Transparency
- Fairness und Bias-Freiheit
Hinzu kommen Tests auf Robustheit, die prüfen, ob sich das Verhalten bei kleinen Prompt-Änderungen unerwartet stark ändert. Ein wichtiger Punkt dsbei: Fine-Tuning kann die ursprünglichen Sicherheitsmechanismen eines Modells unbeabsichtigt verwässern. Das muss systematisch geprüft werden.
In der Praxis empfiehlt sich eine Mischung aus objektiven Metriken wie Latenz, und Token-Ähnlichkeit) sowie subjektiven Kriterien wie Höflichkeit, Kohärenz und Relevanz). Letztere können durch ein anderes LLM bewertet werden. Dabei beurteilt ein größeres, leistungsfähigeres Modell wie GPT-5.5 oder Claude Opus 4.7 die Antworten des feingetunten Modells nach klar definierten Rubriken. Das Problem der „Modell-Amnesie“ und wie man sie verhindert
Das Risiko des katastrophalen Vergessens
Wer ein Modell nachträglich auf neue Aufgaben trainiert, läuft Gefahr, dass es seine ursprünglichen Fähigkeiten vergisst. Dieses Phänomen heißt Catastrophic Forgetting. Ein Modell, das nach dem ersten Fine-Tuning medizinisches Fachwissen demonstrierte, kann nach einer weiteren Trainingsrunde mit juristischen Dokumenten plötzlich Sicherheitsrichtlinien, Formatregeln oder seine Mehrsprachigkeit vergessen.
Die Forschung hat mehrere Lösungsansätze entwickelt:
- Continued Fine-Tuning mit Replay: In den neuen Trainingsdatensatz wird ein repräsentativer Querschnitt der alten Daten eingespeist, damit das Modell nicht vergisst.
- LoRA-Orthogonalität: Statt das Basismodell zu verändern, trainieren Datenwissenschaftler für unterschiedliche Aufgaben separate Adapter. Zur Laufzeit lädt ein Klassifikator dynamisch den passenden Adapter. Die Fähigkeiten bleiben sauber voneinander getrennt.
- Selective Token Masking (STM): Wenn besonders „überraschende“ Tokens während der Gradientenberechnung maskiert werden, lässt sich der destruktive Einfluss auf bestehende Fähigkeiten reduzieren.
- Self-Distillation Fine-Tuning (SDFT): Ein vielversprechender Ansatz, an dem unter anderem das MIT und die ETH Zürich forschen. Das Modell generiert eigene Lösungswege, filtert die erfolgreichen heraus und nutzt sie zur Selbstkorrektur. SDFT kann klassisches Fine-Tuning bei der Zielaufgabe übertreffen und erlaubt es einem einzigen Modell, neue Fähigkeiten aufzubauen, ohne alte zu verlieren.
Fazit
Die wahre Stärke des Fine-Tunings liegt im Anpassen von Verhalten, Format und Jargon bei klar abgegrenzten Aufgaben mit hohem Volumen. Für die meisten Unternehmensszenarien ist RAG kostengünstiger, flexibler und rechtlich besser handhabbar. Erst wenn das Abfragevolumen sehr hoch wird, strikte Compliance-Anforderungen lokale Lösungen erzwingen oder eine extrem niedrige Latenz gefordert ist, lohnt sich der Aufwand.
Die elegante Lösung lautet in vielen Fällen ohnehin: beides kombinieren. Wer die regulatorischen Implikationen ernst nimmt, die Kosten realistisch kalkuliert und technische Methoden wie QLoRA klug einsetzt, kann KI-Modelle zu echten Spezialisten für die eigene Domäne machen. Und vermeidet zugleich, dass aus dem Projekt ein teurer Lernprozess wird.
Ihr Wartungsspezialist für alle großen Hardware Hersteller
Durch Jahrzehnte lange Erfahrung wissen wir worauf es bei der Wartung Ihrer Data Center Hardware ankommt. Profitieren Sie nicht nur von unserer Erfahrung, sondern auch von unseren ausgezeichneten Preisen. Holen Sie sich ein unverbindliches Angebot und vergleichen Sie selbst.
Weitere Artikel

Claude for Small Business: KI für kleine Unternehmen als Chance oder Risiko?
Künstliche Intelligenz hat den deutschen Mittelstand als tägliches Werkzeug in vielen Anwendungsbereichen erreicht. Für viele kleine Betriebe ist KI

Wer die GPUs kontrolliert, kontrolliert die KI-Zukunft
Shownotes Die große These KI wird zur Infrastrukturindustrie. Wer GPUs, Strom, Datacenter, Modelle und Sicherheitswerkzeuge kontrolliert, kontrolliert einen
Fine-Tuning: wie Unternehmen KI-Modelle mit eigenen Daten nachtrainieren können
Wer ein Modell wie GPT, Claude oder Mistral so einsetzen möchte, dass es den eigenen Fachjargon beherrscht, juristisch sauber arbeitet
